总结过一些redis与数据库保持一致的文章redis与数据库保持一致的几种方式,今天更理论化一些,记录一下。
主要参考 高并发系统设计40问
https://time.geekbang.org/column/article/150881
Cache Aside(旁路缓存)策略
在更新数据时不更新缓存,而是删除缓存中的数据,在读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。
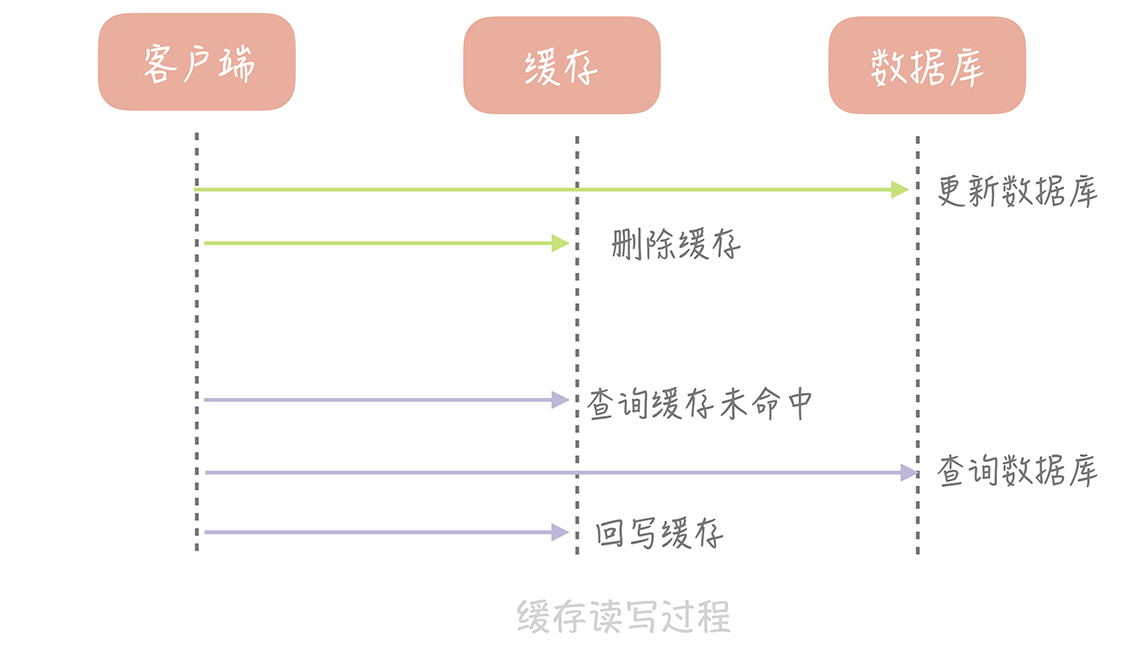
Cache Aside 策略(也叫旁路缓存策略),这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。
它可以分为读策略和写策略,其中读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是: - 更新数据库中的记录;
- 删除缓存记录。
注意,是先更新数据库,再删除缓存,否则,在并发情况下可能导致缓存和数据不一致。参考下面的场景,会出现数据不一致。
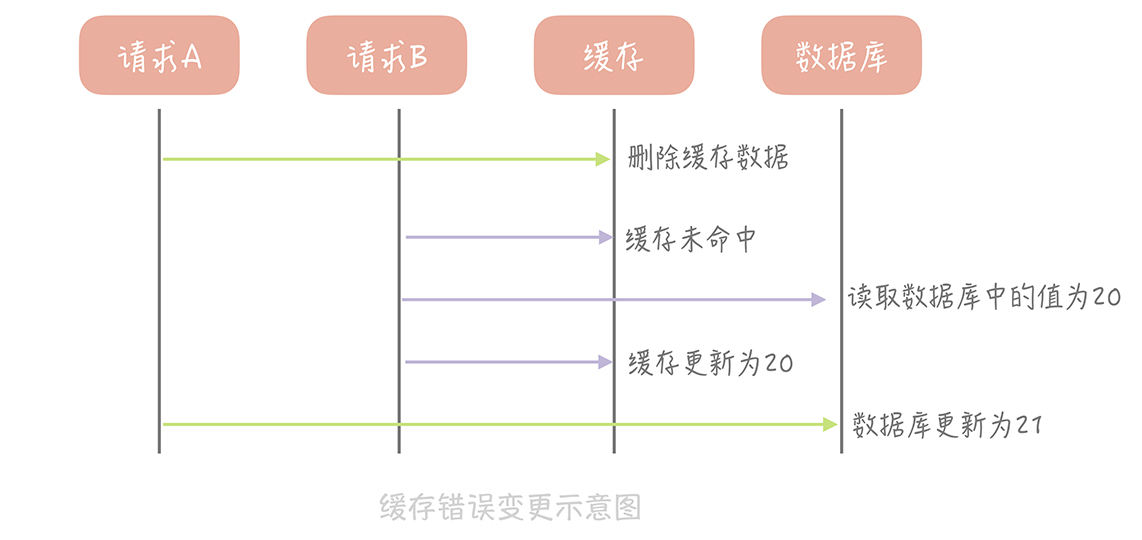
不过cash-aside也不是完美的,
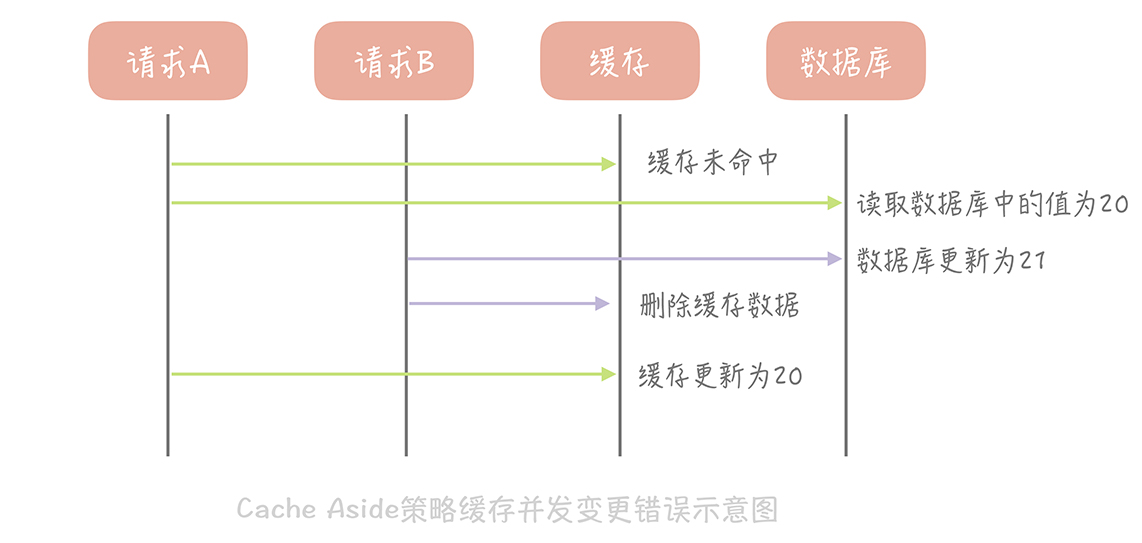
如上图,会有数据不一致。存的写入通常远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且清空了缓存,请求 A 才更新完缓存的情况。而一旦请求 A 早于请求 B 清空缓存之前更新了缓存,那么接下来的请求就会因为缓存为空而从数据库中重新加载数据,所以不会出现这种不一致的情况。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。
Read/Write Through(读穿 / 写穿)策略
策略的核心原则是用户只与缓存打交道,由缓存和数据库通信,写入或者读取数据。
Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。
一般来说,我们可以选择两种“Write Miss”方式:一个是“Write Allocate(按写分配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;另一个是“No-write allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中。在 Write Through 策略中,我们一般选择“No-write allocate”方式,原因是无论采用哪种“Write Miss”方式,我们都需要同步将数据更新到数据库中,而“No-write allocate”方式相比“Write Allocate”还减少了一次缓存的写入,能够提升写入的性能。
Read Through 策略就简单一些,它的步骤是这样的:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。
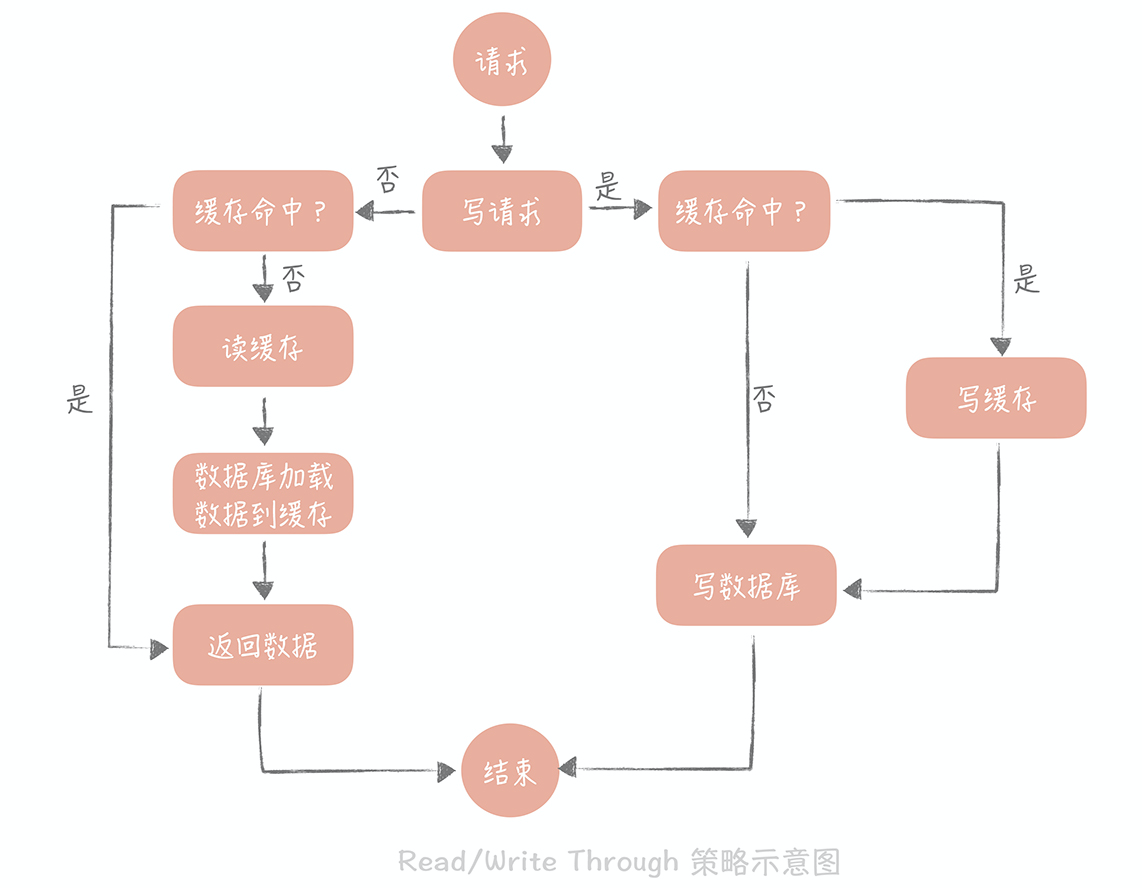
Read Through/Write Through 策略的特点是由缓存节点而非用户来和数据库打交道,在我们开发过程中相比 Cache Aside 策略要少见一些,原因是我们经常使用的分布式缓存组件,无论是 Memcached 还是 Redis 都不提供写入数据库,或者自动加载数据库中的数据的功能。而我们在使用本地缓存的时候可以考虑使用这种策略,比如说在上一节中提到的本地缓存 Guava Cache 中的 Loading Cache 就有 Read Through 策略的影子。
Write Back(写回)策略
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。
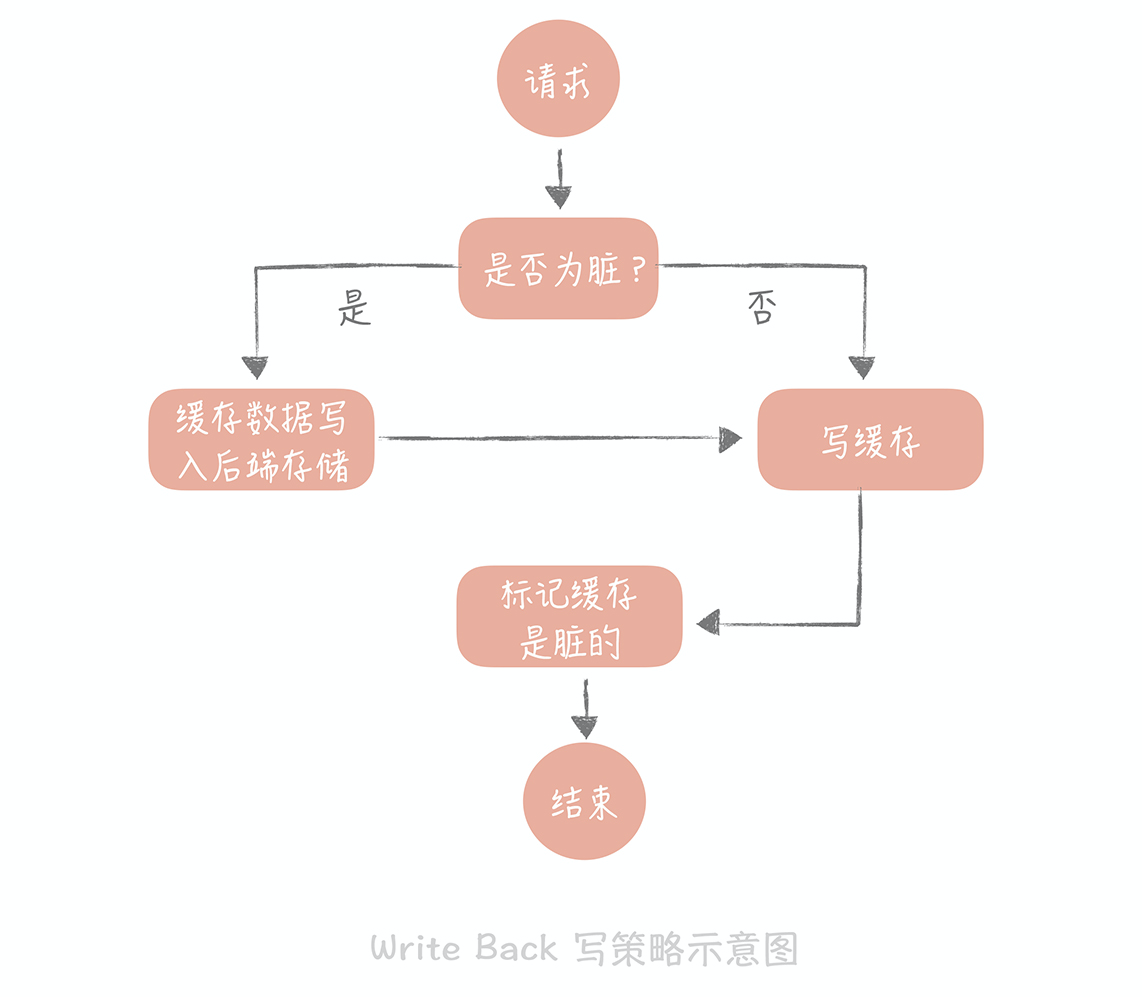
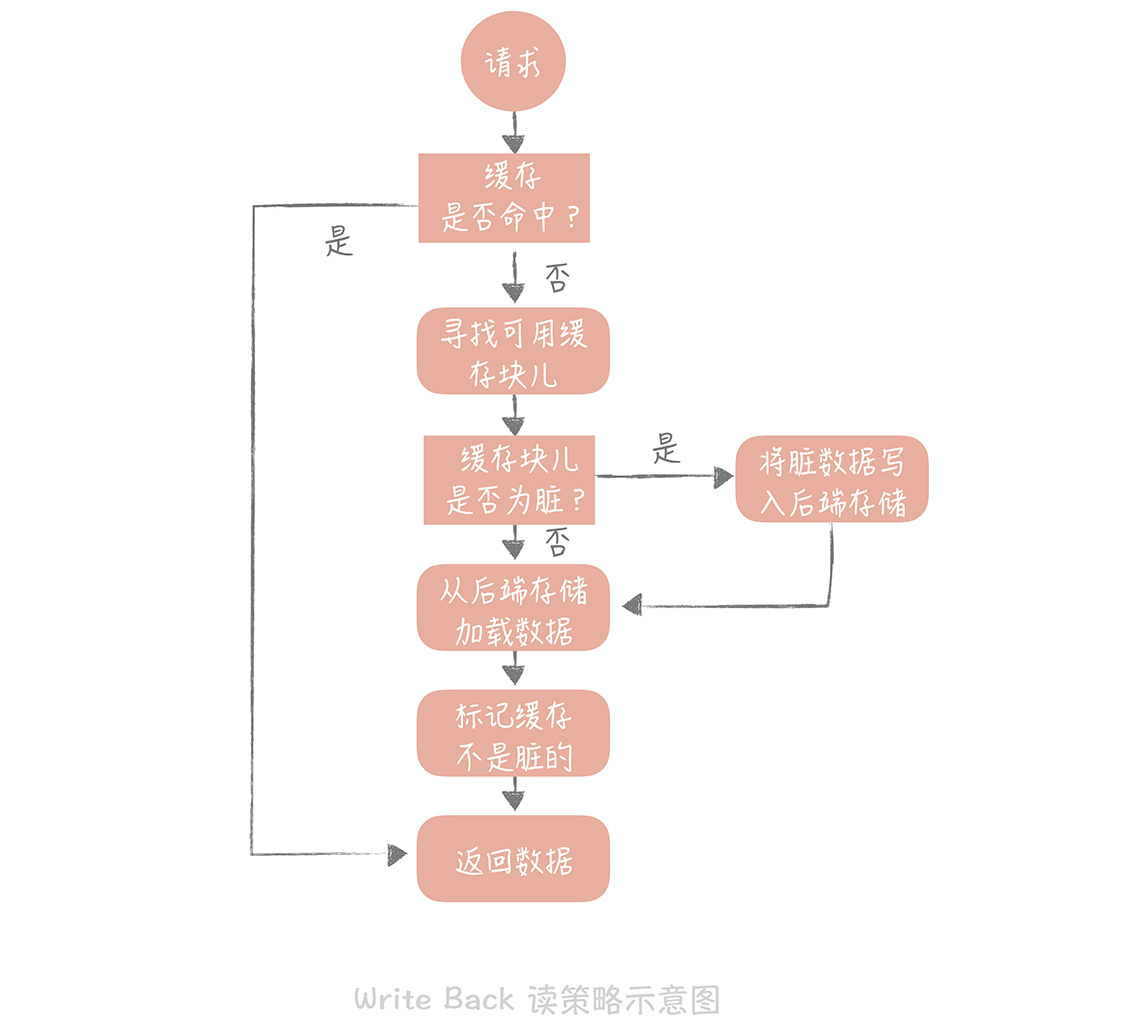
如果使用 Write Back 策略的话,读的策略也有一些变化了。我们在读取缓存时如果发现缓存命中则直接返回缓存数据。如果缓存不命中则寻找一个可用的缓存块儿,如果这个缓存块儿是“脏”的,就把缓存块儿中之前的数据写入到后端存储中,并且从后端存储加载数据到缓存块儿,如果不是脏的,则由缓存组件将后端存储中的数据加载到缓存中,最后我们将缓存设置为不是脏的,返回数据就好了。
其实这种策略不能被应用到我们常用的数据库和缓存的场景中,它是计算机体系结构中的设计,比如我们在向磁盘中写数据时采用的就是这种策略。无论是操作系统层面的 Page Cache,还是日志的异步刷盘,亦或是消息队列中消息的异步写入磁盘,大多采用了这种策略。因为这个策略在性能上的优势毋庸置疑,它避免了直接写磁盘造成的随机写问题,毕竟写内存和写磁盘的随机 I/O 的延迟相差了几个数量级呢。但因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏块儿数据丢失。所以你会发现系统在掉电之后,之前写入的文件会有部分丢失,就是因为 Page Cache 还没有来得及刷盘造成的。
当然,你依然可以在一些场景下使用这个策略,在使用时,我想给你的落地建议是:你在向低速设备写入数据的时候,可以在内存里先暂存一段时间的数据,甚至做一些统计汇总,然后定时地刷新到低速设备上。比如说,你在统计你的接口响应时间的时候,需要将每次请求的响应时间打印到日志中,然后监控系统收集日志后再做统计。但是如果每次请求都打印日志无疑会增加磁盘 I/O,那么不如把一段时间的响应时间暂存起来,经过简单的统计平均耗时,每个耗时区间的请求数量等等,然后定时地,批量地打印到日志中。