spark
大数据计算就是在大规模的数据集上进行一系列的数据计算处理。MapReduce 针对输入数据,将计算过程分为两个阶段,一个 Map 阶段,一个 Reduce 阶段,可以理解成是面向过程的大数据计算。我们在用 MapReduce 编程的时候,思考的是,如何将计算逻辑用 Map 和 Reduce 两个阶段实现,map 和 reduce 函数的输入和输出是什么,这也是我们在学习 MapReduce 编程的时候一再强调的。
而 Spark 则直接针对数据进行编程,将大规模数据集合抽象成一个 RDD 对象,然后在这个 RDD 上进行各种计算处理,得到一个新的 RDD,继续计算处理,直到得到最后的结果数据。所以 Spark 可以理解成是面向对象的大数据计算。我们在进行 Spark 编程的时候,思考的是一个 RDD 对象需要经过什么样的操作,转换成另一个 RDD 对象,思考的重心和落脚点都在 RDD 上。
spark的特点
- DAG切分的多阶段计算过程更快速
- 使用内存存储中间过程结果更高效
- RDD编程模型更简单
RDD
RDD 是 Spark 的核心概念,是弹性数据集(Resilient Distributed Datasets)的缩写。RDD 既是 Spark 面向开发者的编程模型,又是 Spark 自身架构的核心元素。
RDD 上定义的函数分两种,一种是转换(transformation)函数,这种函数的返回值还是 RDD;另一种是执行(action)函数,这种函数不再返回 RDD。
RDD 定义了很多转换操作函数,比如有计算 map(func)、过滤 filter(func)、合并数据集 union(otherDataset)、根据 Key 聚合 reduceByKey(func, [numPartitions])、连接数据集 join(otherDataset, [numPartitions])、分组 groupByKey([numPartitions]) 等十几个函数。
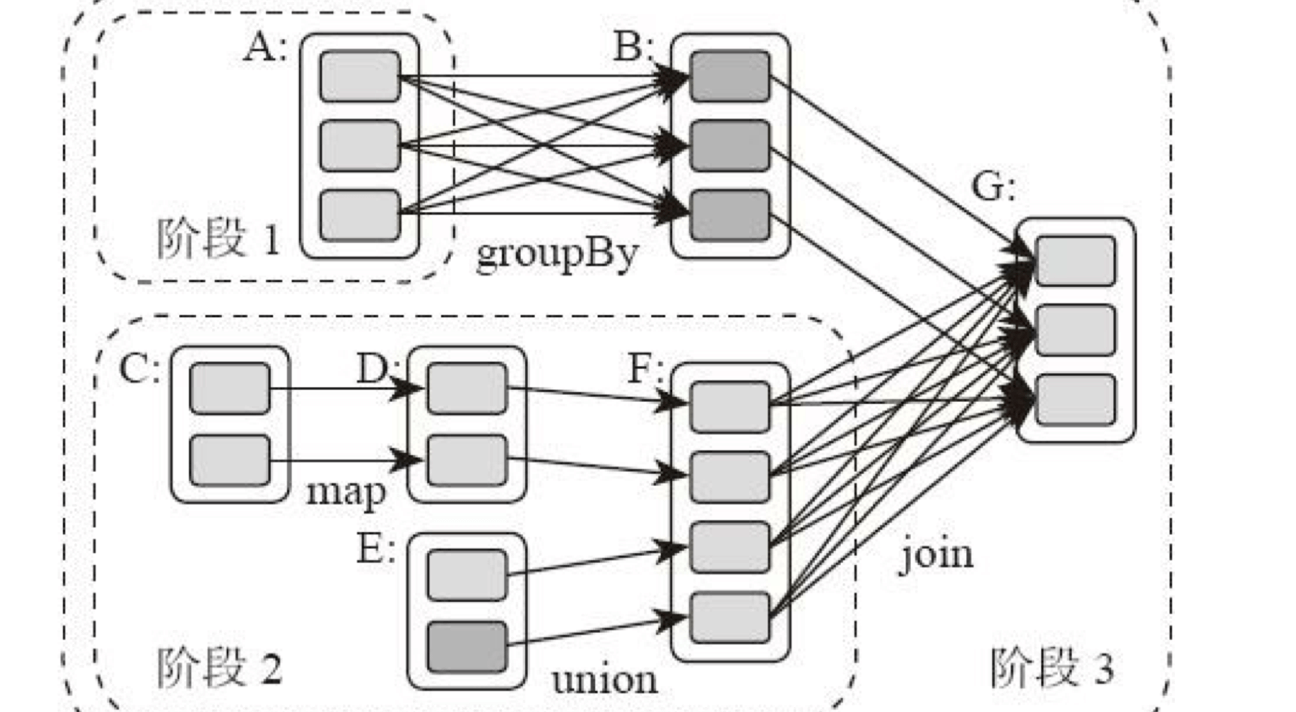
作为 Spark 架构核心元素的 RDD。跟 MapReduce 一样,Spark 也是对大数据进行分片计算,Spark 分布式计算的数据分片、任务调度都是以 RDD 为单位展开的,每个 RDD 分片都会分配到一个执行进程去处理。RDD 上的转换操作又分成两种,一种转换操作产生的 RDD 不会出现新的分片,比如 map、filter 等,也就是说一个 RDD 数据分片,经过 map 或者 filter 转换操作后,结果还在当前分片。就像你用 map 函数对每个数据加 1,得到的还是这样一组数据,只是值不同。实际上,Spark 并不是按照代码写的操作顺序去生成 RDD,比如rdd2 = rdd1.map(func)这样的代码并不会在物理上生成一个新的 RDD。物理上,Spark 只有在产生新的 RDD 分片时候,才会真的生成一个 RDD,Spark 的这种特性也被称作惰性计算。另一种转换操作产生的 RDD 则会产生新的分片,比如reduceByKey,来自不同分片的相同 Key 必须聚合在一起进行操作,这样就会产生新的 RDD 分片。
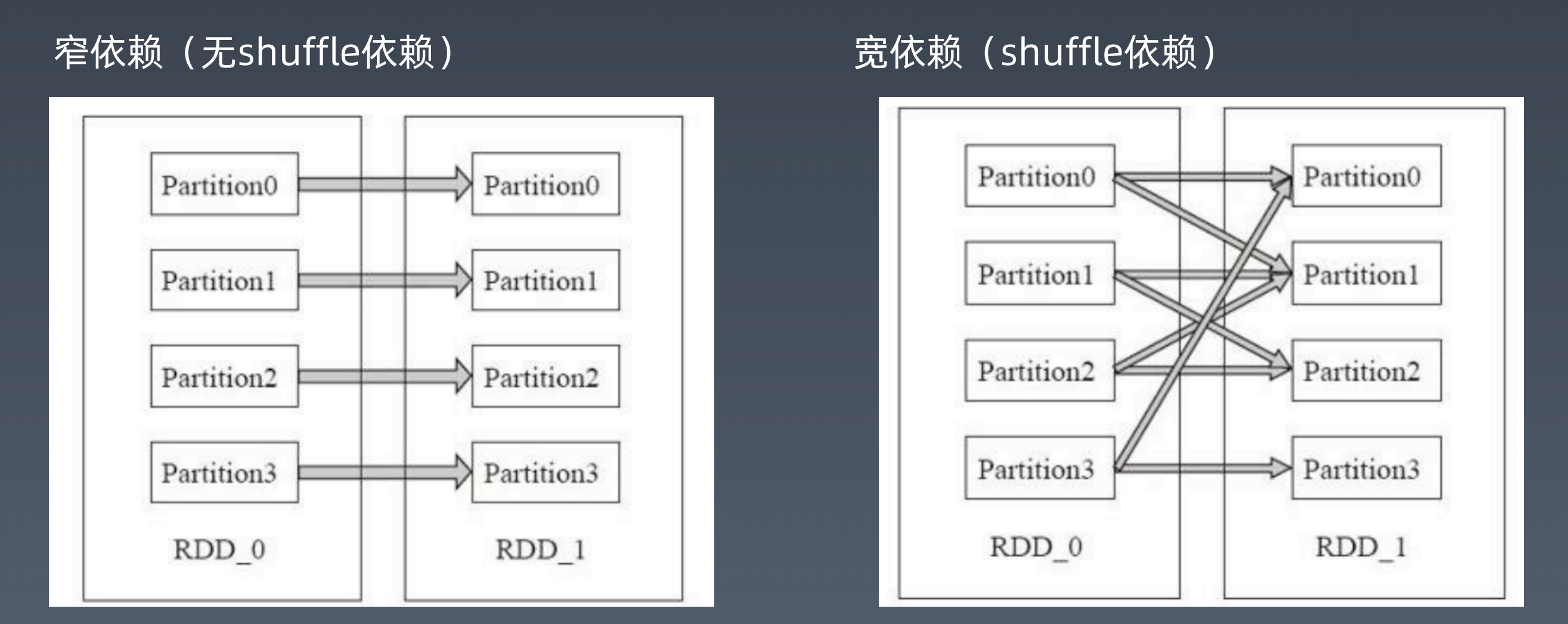
宽依赖、窄依赖
spark的执行过程
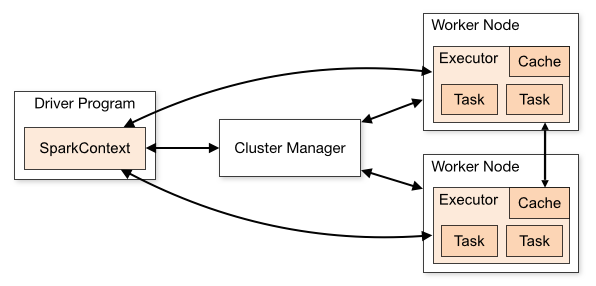
Spark 支持 Standalone、Yarn、Mesos、Kubernetes 等多种部署方案,几种部署方案原理也都一样,只是不同组件角色命名不同,但是核心功能和运行流程都差不多。
首先,Spark 应用程序启动在自己的 JVM 进程里,即 Driver 进程,启动后调用 SparkContext 初始化执行配置和输入数据。SparkContext 启动 DAGScheduler 构造执行的 DAG 图,切分成最小的执行单位也就是计算任务。
然后 Driver 向 Cluster Manager 请求计算资源,用于 DAG 的分布式计算。Cluster Manager 收到请求以后,将 Driver 的主机地址等信息通知给集群的所有计算节点 Worker。
Worker 收到信息以后,根据 Driver 的主机地址,跟 Driver 通信并注册,然后根据自己的空闲资源向 Driver 通报自己可以领用的任务数。Driver 根据 DAG 图开始向注册的 Worker 分配任务。
Worker 收到任务后,启动 Executor 进程开始执行任务。Executor 先检查自己是否有 Driver 的执行代码,如果没有,从 Driver 下载执行代码,通过 Java 反射加载后开始执行。
流计算
storm
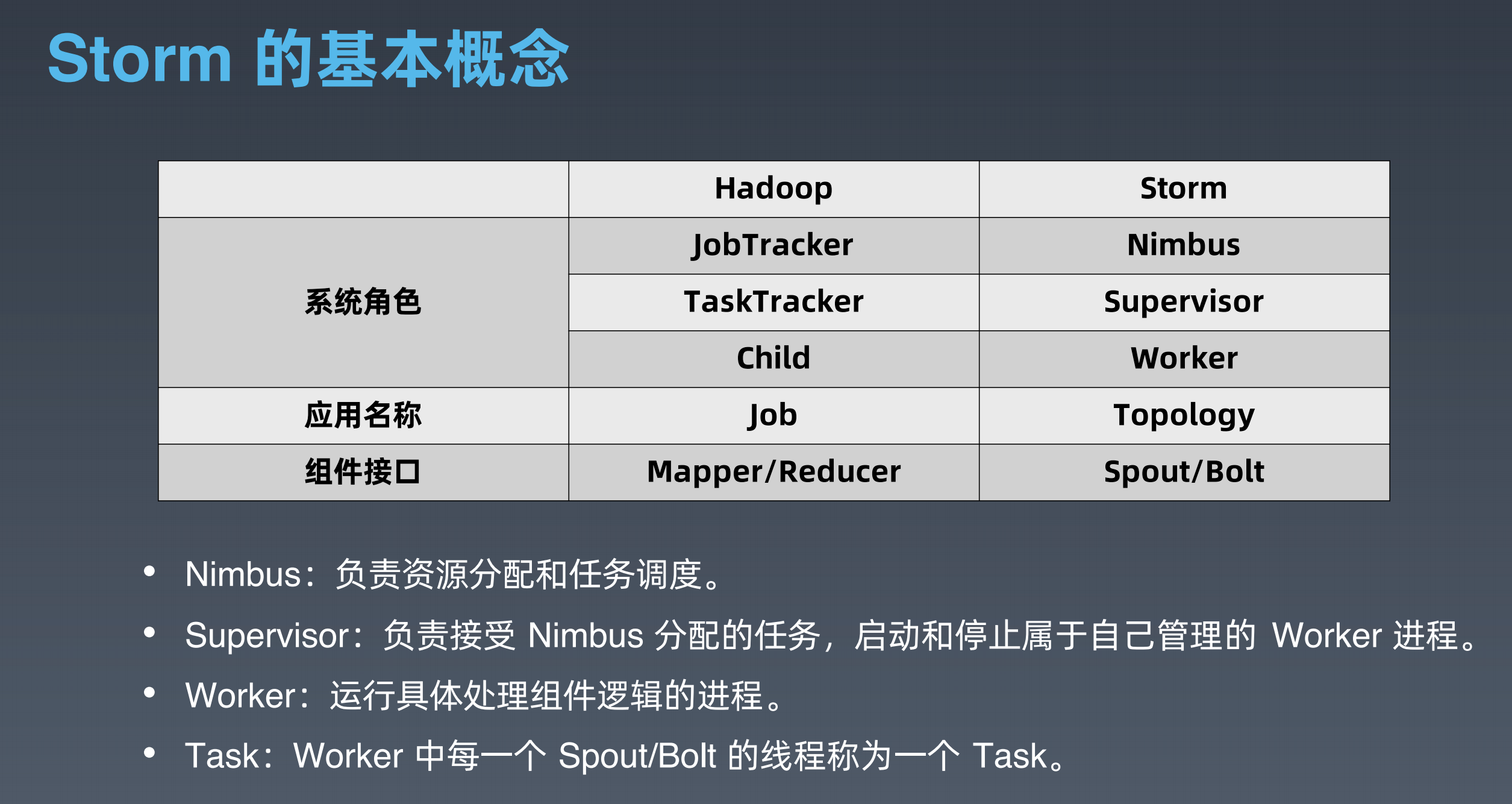
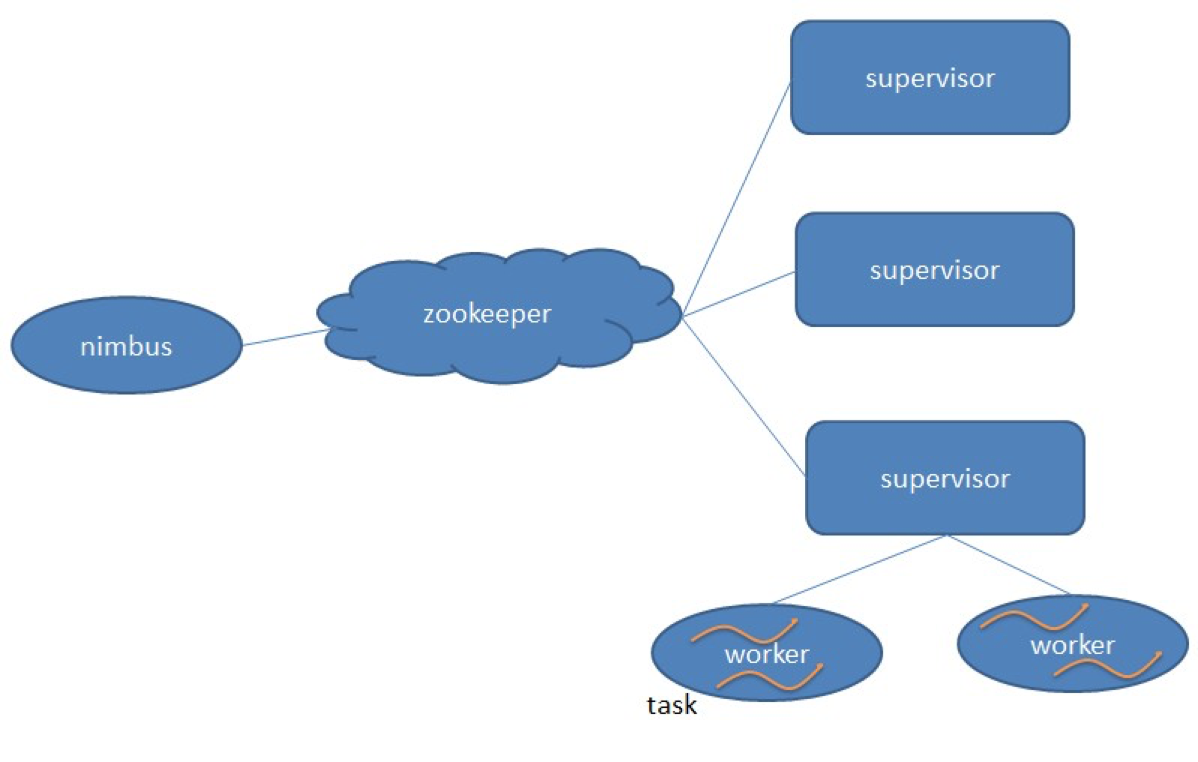
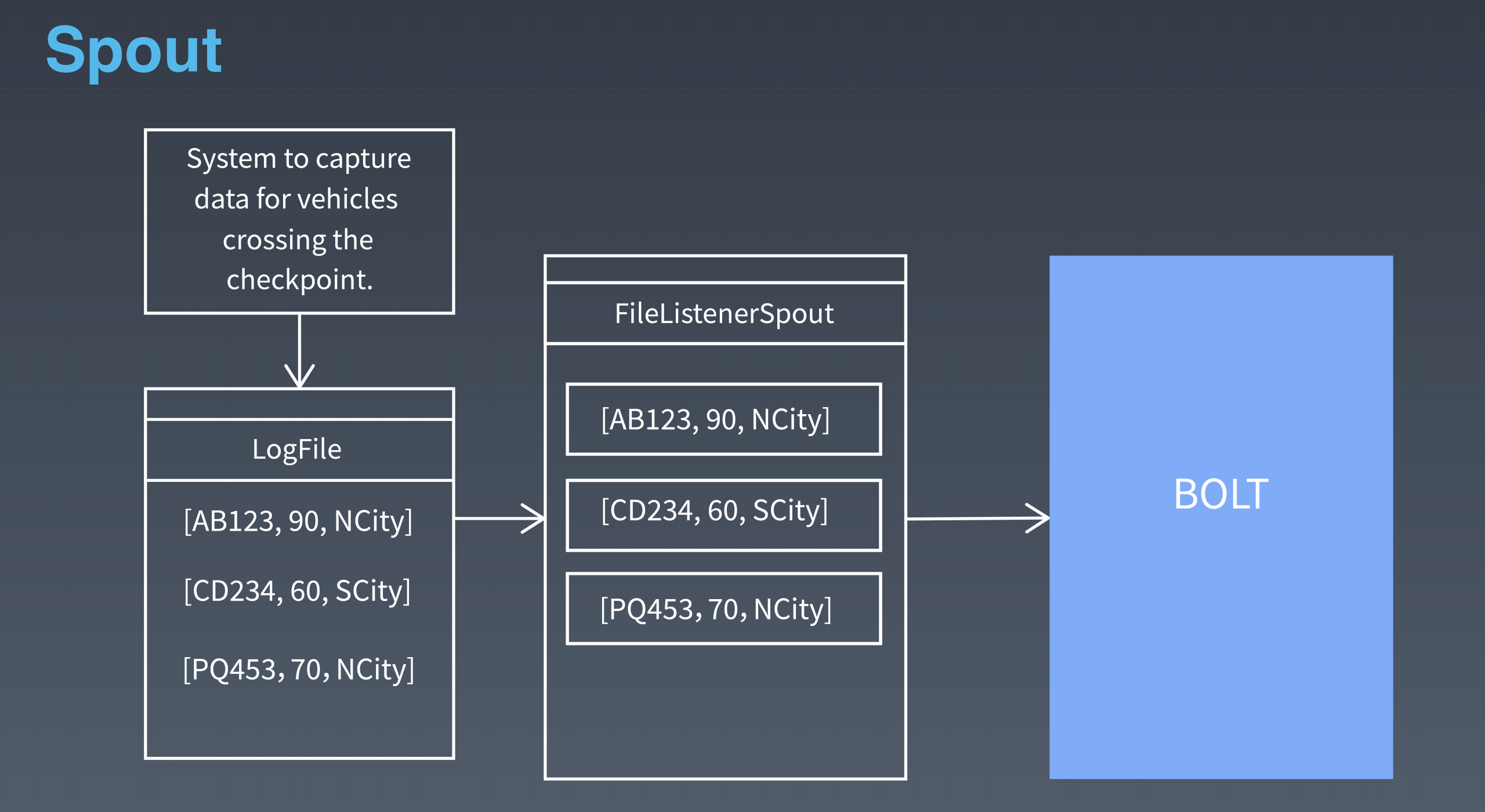
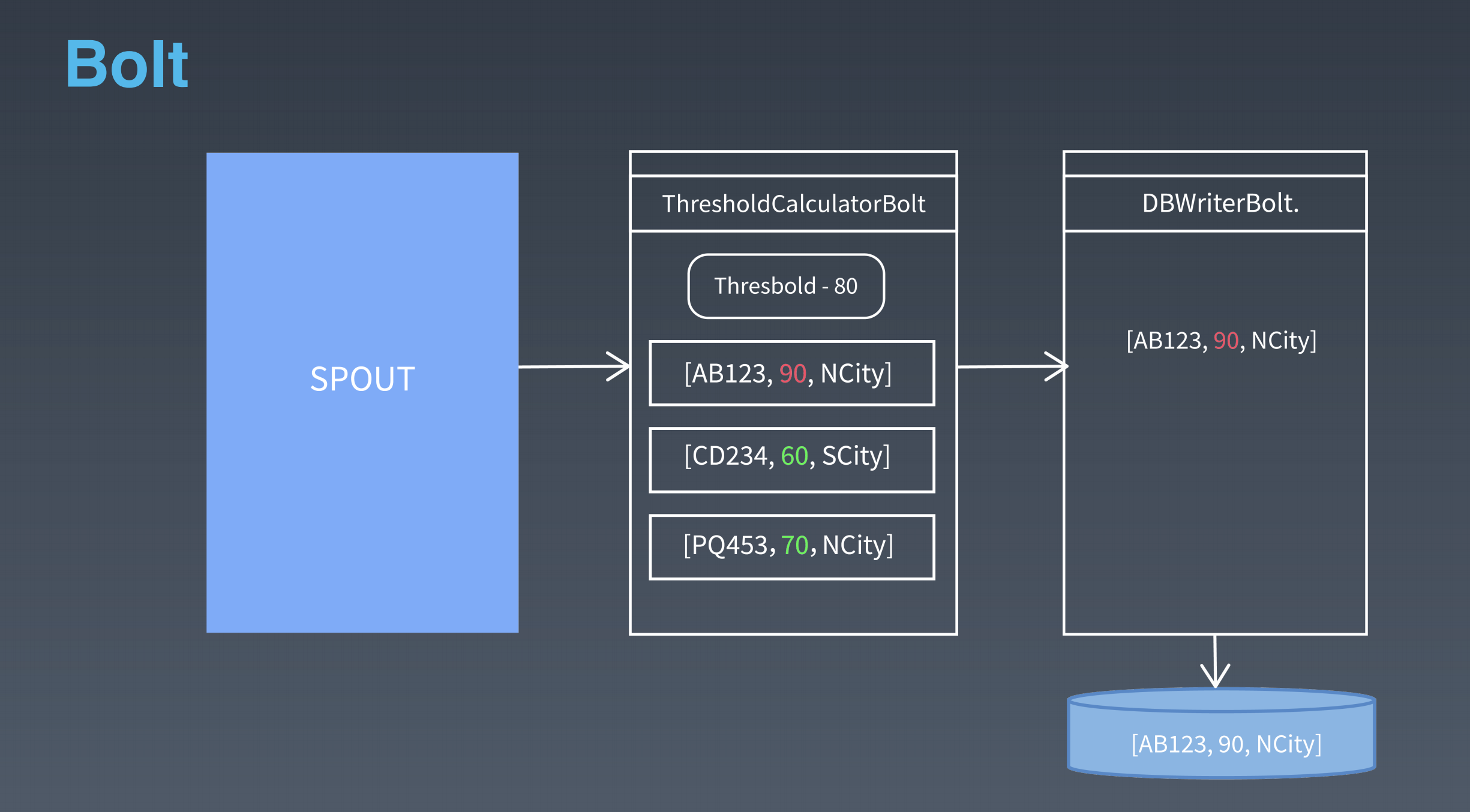
nimbus 是集群的 Master,负责集群管理、任务分配等。supervisor 是 Slave,是真正完成计算的地方,每个 supervisor 启动多个 worker 进程,每个 worker 上运行多个 task,而 task 就是 spout 或者 bolt。supervisor 和 nimbus 通过 ZooKeeper 完成任务分配、心跳检测等操作。
spark streaming
Spark Streaming 巧妙地利用了 Spark 的分片和快速计算的特性,将实时传输进来的数据按照时间进行分段,把一段时间传输进来的数据合并在一起,当作一批数据,再去交给 Spark 去处理。

Flink
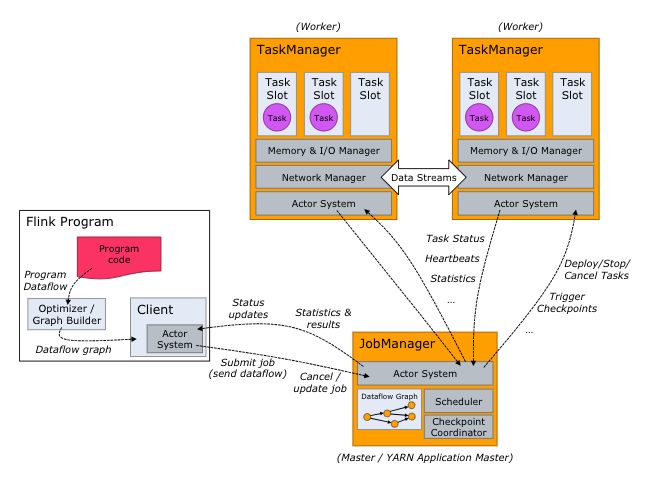
Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream edits = see.addSource(new WikipediaEditsSource());
如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSet text = env.readTextFile(“/path/to/file”);
然后在 DataStream 或者 DataSet 上执行各种数据转换操作(transformation),这点很像 Spark。
不管是流处理还是批处理,Flink 运行时的执行引擎是相同的,只是数据源不同而已。Flink 处理实时数据流的方式跟 Spark Streaming 也很相似,也是将流数据分段后,一小批一小批地处理。流处理算是 Flink 里的“一等公民”,Flink 对流处理的支持也更加完善,它可以对数据流执行 window 操作,将数据流切分到一个一个的 window 里,进而进行计算。
在数据流上执行.timeWindow(Time.seconds(10))可以将数据切分到一个 10 秒的时间窗口,进一步对这个窗口里的一批数据进行统计汇总。Flink 的架构和 Hadoop 1 或者 Yarn 看起来也很像,JobManager 是 Flink 集群的管理者,Flink 程序提交给 JobManager 后,JobManager 检查集群中所有 TaskManager 的资源利用状况,如果有空闲 TaskSlot(任务槽),就将计算任务分配给它执行。
大数据可视化
互联网运营常用数据指标
- 新增用户数
- 用户留存率
- 活跃用户数
- PV(page view)
- GMV 成交总金额
- 转化率
大数据算法与机器学习
PageRank

KNN分类算法
“近朱者赤,近墨者黑”可以说是 KNN 的工作原理。整个计算过程分为三步:
- 计算待分类物体与其他物体之间的距离;
- 统计距离最近的 K 个邻居;
- 对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
关于距离的计算方式有下面五种方式:欧氏距离;曼哈顿距离;闵可夫斯基距离;切比雪夫距离;余弦距离。
TF-IDF

朴素贝叶斯分类
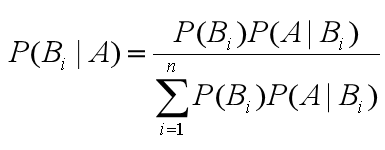
K-means
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,你可以理解这个算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。
K-Means 的工作原理总结下:
- 选取 K 个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
- 将每个点分配到最近的类中心点,这样就形成了 K 个类,然后重新计算每个类的中心点;
- 重复第二步,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束。
推荐引擎算法
- 基于人口推荐
- 基于商品属性的推荐
- 基于用户的协同过滤推荐
- 基于商品的协同过滤推荐
机器学习架构
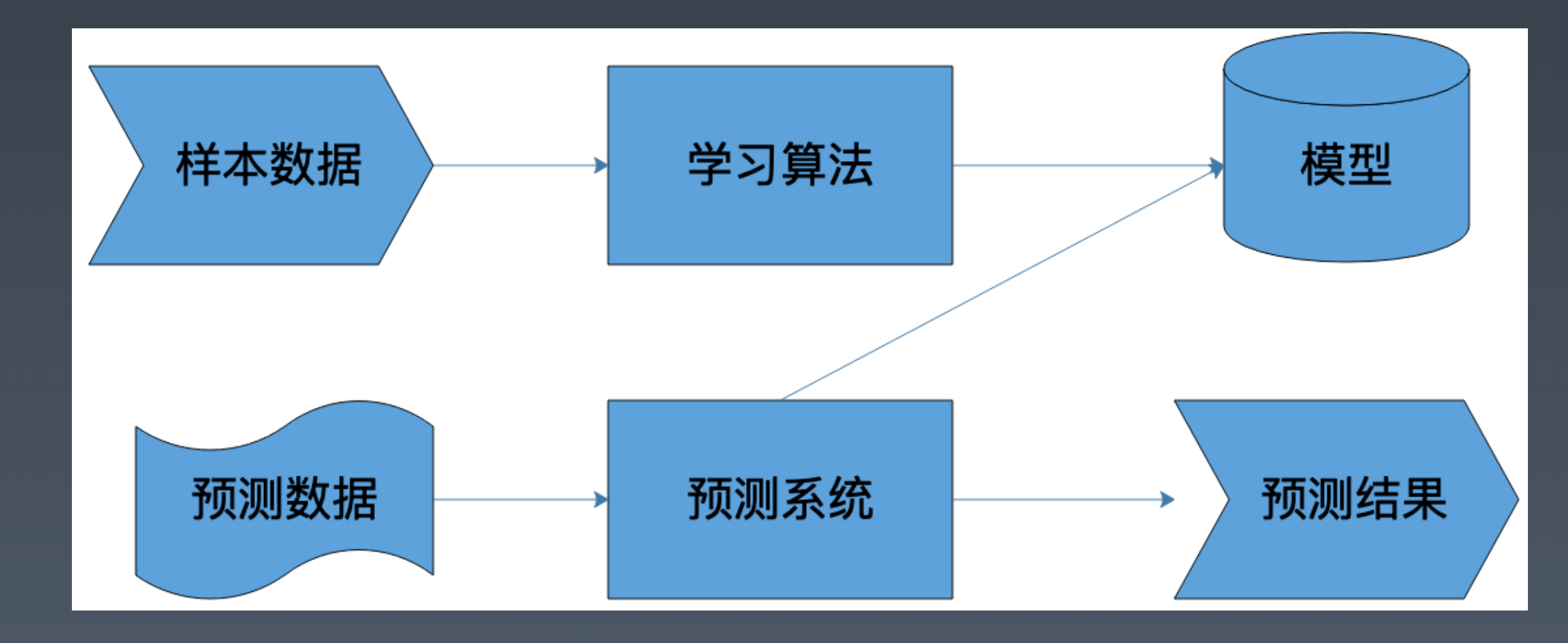
模型
算法
样本
感知机
神经网络