CAP原理(https://time.geekbang.org/column/article/9302):
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer’s theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance – one of them must be sacrificed.
1.一致性
A read is guaranteed to return the most recent write for a given client.
对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
2.可用性
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
3.分区容忍性(Partition Tolerance)
The system will continue to function when network partitions occur.
当出现网络分区后,系统能够继续“履行职责”。
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。如果我们选择了 CA 而放弃了 P,那么当发生分区现象时,为了保证 C,系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A 冲突了,因为 A 要求返回 no error 和 no timeout。因此,分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
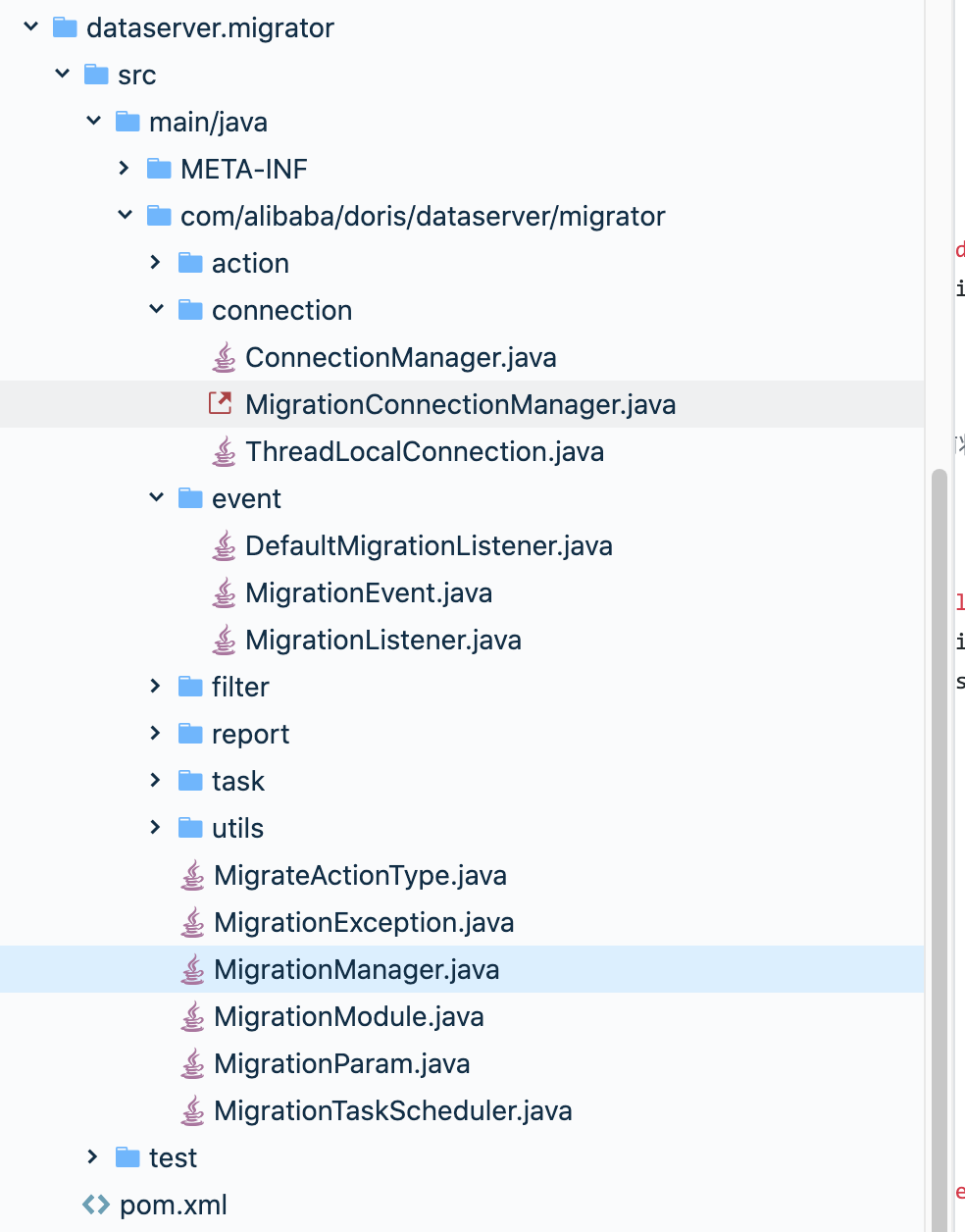
1.CP – Consistency/Partition Tolerance如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
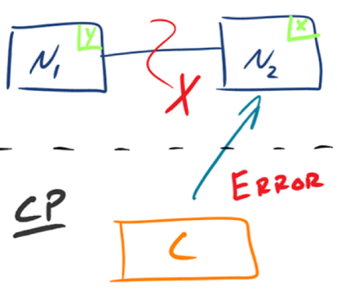
2.AP – Availability/Partition Tolerance如下图所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
CAP需要注意的细节
- CAP 关注的粒度是数据,而不是整个系统。
在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,有的数据必须选择 CP,有的数据必须选择 AP。而如果我们做设计时,从整个系统的角度去选择 CP 还是 AP,就会发现顾此失彼,无论怎么做都是有问题的。所以在 CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类
2. CAP是忽略网络延迟的
这是一个非常隐含的假设,布鲁尔在定义一致性时,并没有将延迟考虑进去。也就是说,当事务提交时,数据能够瞬间复制到所有节点。但实际情况下,从节点 A 复制数据到节点 B,总是需要花费一定时间的。如果是相同机房,耗费时间可能是几毫秒;如果是跨地域的机房,例如北京机房同步到广州机房,耗费的时间就可能是几十毫秒。这就意味着,CAP 理论中的 C 在实践中是不可能完美实现的,在数据复制的过程中,节点 A 和节点 B 的数据并不一致。不要小看了这几毫秒或者几十毫秒的不一致,对于某些严苛的业务场景,例如和金钱相关的用户余额,或者和抢购相关的商品库存,技术上是无法做到分布式场景下完美的一致性的。而业务上必须要求一致性,因此单个用户的余额、单个商品的库存,理论上要求选择 CP 而实际上 CP 都做不到,只能选择 CA。也就是说,只能单点写入,其他节点做备份,无法做到分布式情况下多点写入。
3. 正常运行情况下,不存在 CP 和 AP 的选择,可以同时满足 CA。
CAP 理论告诉我们分布式系统只能选择 CP 或者 AP,但其实这里的前提是系统发生了“分区”现象。如果系统没有发生分区现象,也就是说 P 不存在的时候(节点间的网络连接一切正常),我们没有必要放弃 C 或者 A,应该 C 和 A 都可以保证,这就要求架构设计的时候既要考虑分区发生时选择 CP 还是 AP,也要考虑分区没有发生时如何保证 CA。
4. 放弃并不等于什么都不做,需要为分区恢复后做准备。
CAP 理论告诉我们三者只能取两个,需要“牺牲”(sacrificed)另外一个,这里的“牺牲”是有一定误导作用的,因为“牺牲”让很多人理解成什么都不做。实际上,CAP 理论的“牺牲”只是说在分区过程中我们无法保证 C 或者 A,但并不意味着什么都不做。因为在系统整个运行周期中,大部分时间都是正常的,发生分区现象的时间并不长。例如,99.99% 可用性(俗称 4 个 9)的系统,一年运行下来,不可用的时间只有 50 分钟;99.999%(俗称 5 个 9)可用性的系统,一年运行下来,不可用的时间只有 5 分钟。分区期间放弃 C 或者 A,并不意味着永远放弃 C 和 A,我们可以在分区期间进行一些操作,从而让分区故障解决后,系统能够重新达到 CA 的状态。
Doris故障解决方案
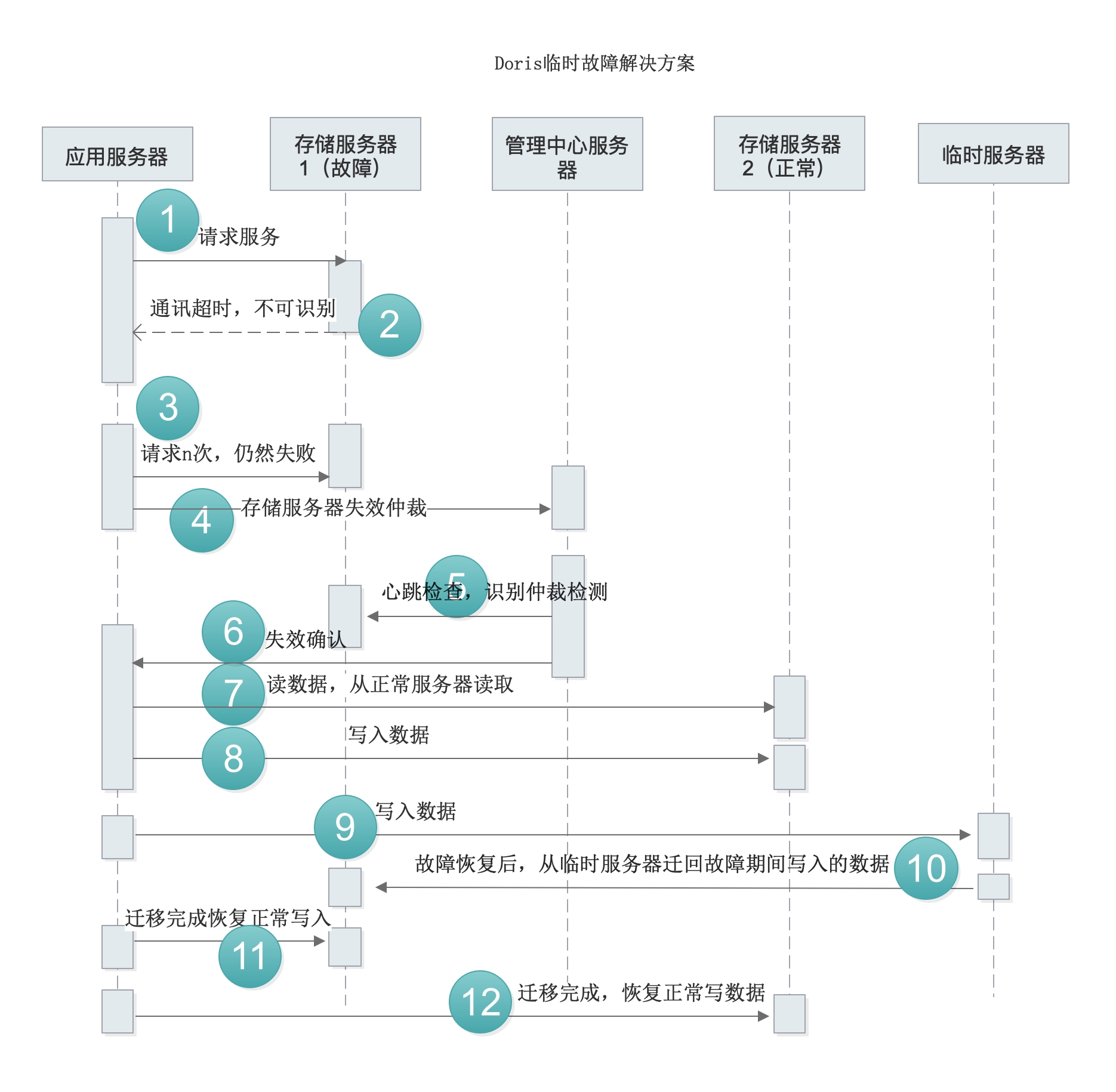
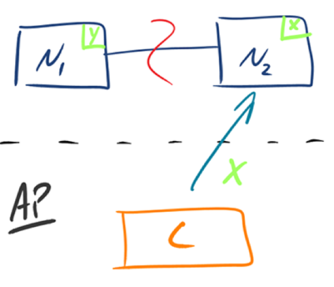
对恢复部分的理解有些简单,按照老师的介绍修改了部分内容
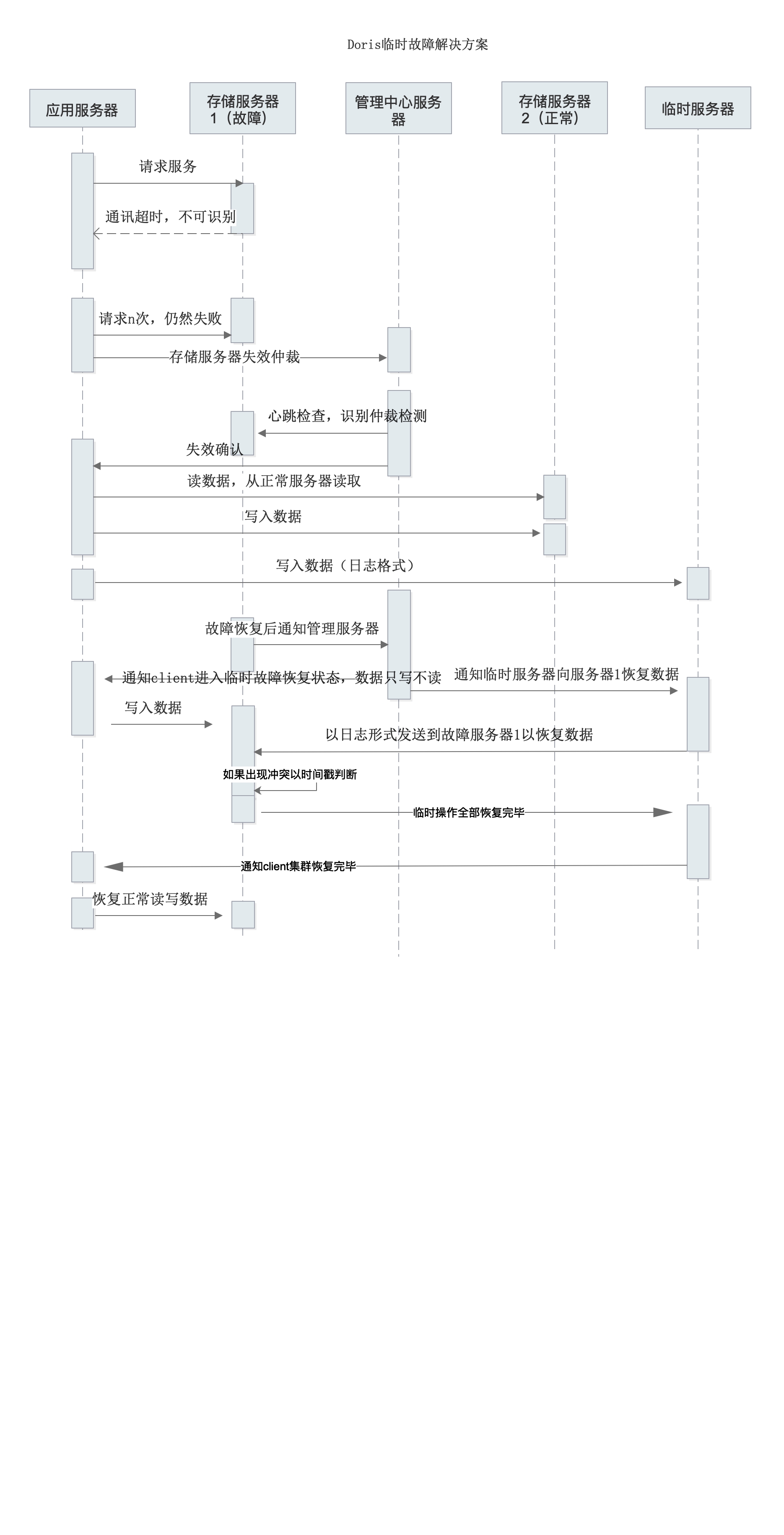
节点迁移的代码,主要在这个模块下面