数据结构与算法
数据结构与算法是计算机的基础,展开来是一个宏大的话题。
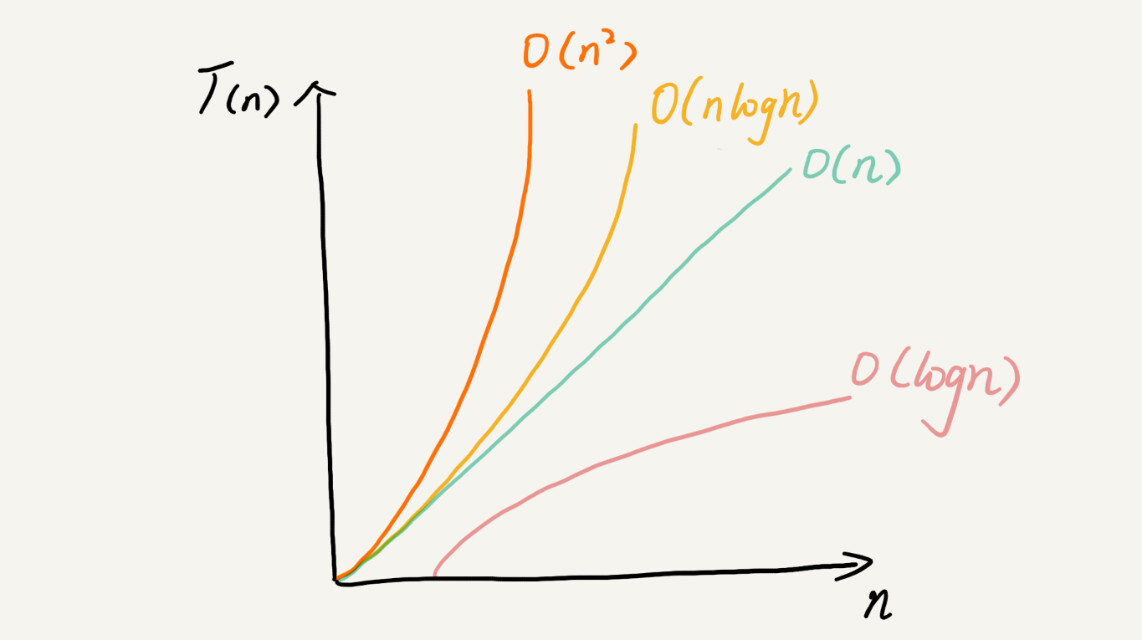
时间和空间复杂度的大O表示法:基础知识,所有学习算法的人都要一开始了解的知识
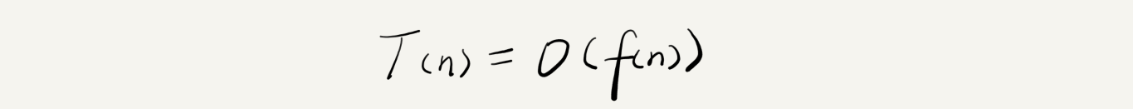
所有代码的执行时间 T(n) 与每行代码的执行次数 n 成正比。
大 O 时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。

P和NP问题
P问题:能在多项式时间复杂度内解决的问题
NP问题:能在多项式时间复杂度内验证答案正取与否的问题
NP =? P
NP-hard:比NP问题更难的问题(NP问题的解法可以规约到NP-hard问题的解法)
NP完全问题:是一个NP-hard问题,也是一个NP问题

P对NP问题实际上是指,是否每个NP问题都有一个P解,或者是否存在通过P绝对不能解决的NP问题。虽然P≠NP看似显而易见,但它并没有经过严格的数学证明。如果能够证明P=NP意味着多项式时间算法适用于很多非常重要的计算机问题,届时揭开比特币的神秘面纱显然不再是件难事儿,毕竟比特币挖掘和安全密钥都依赖于难以解决却易于验证的NP问题
NP问题平时我在工作中关注的不多,最近一次关注还是因为王垠和P10的口水事件。。。
数组
根据数组的下标访问数据,时间复杂度为O(1)。针对数组类型,很多语言都提供了容器类,比如 Java 中的 ArrayList、C++ STL 中的 vector。ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容
链表
一般来说链表中增删数据性能比数组好
利用哨兵简化实现难度。如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
链表处理中的一些总结:
1、 函数中需要移动链表时,最好新建一个指针来移动,以免更改原始指针位置。
2、 单链表有带头节点和不带头结点的链表之分,一般做题默认头结点是有值的。
3、 链表的内存时不连续的,一个节点占一块内存,每块内存中有一块位置(next)存放下一节点的地址(这是单链表为例)。
3、 链表中找环的思想:创建两个指针一个快指针一次走两步一个慢指针一次走一步,若相遇则有环,若先指向nullptr则无环。
4、 链表找倒数第k个节点思想:创建两个指针,第一个先走k-1步然后两个在一同走。第一个走到最后时则第二个指针指向倒数第k位置。
5、 反向链表思想:从前往后将每个节点的指针反向,即.next内的地址换成前一个节点的,但为了防止后面链表的丢失,在每次换之前需要先创建个指针指向下一个节点。
6、 两个有序链表合并思想:这里用到递归思想。先判断是否有一个链表是空链表,是则返回两一个链表,免得指针指向不知名区域引发程序崩溃。然后每次比较两个链表的头结点,小的值做新链表的头结点,此节点的next指针指向本函数(递归开始,参数是较小值所在链表.next和另一个链表)。
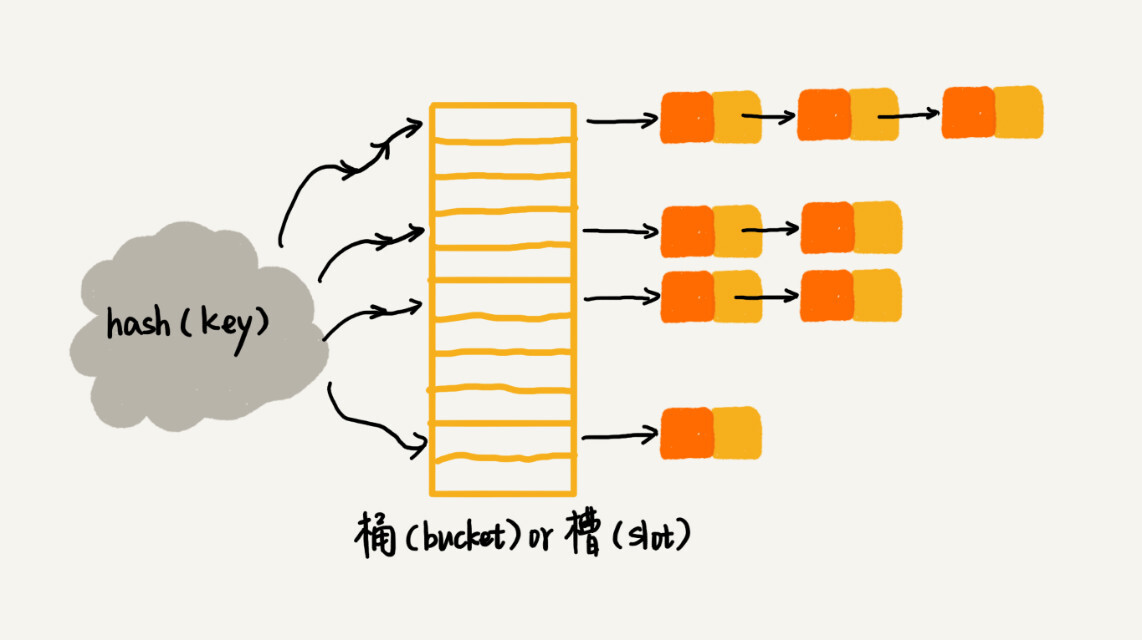
hash表
常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)
开放寻址法
- 线性探测法
- 二次探测法
- 双重散列
链表法
栈 后进先出
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
在实际工作中,java里使用dequeue。在队尾操作来实现stack的功能
队列 先进先出
树、图的广度优先遍历使用队列进行处理
java的并发容器里有一堆的queue
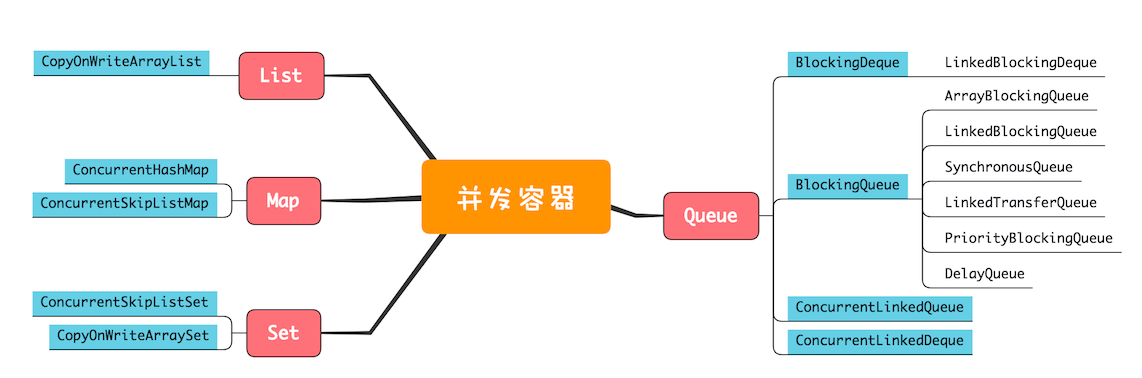
我们使用的各种消息队列中间件,本质上也是队列
- activemq
- kafka
- RocketMQ
- RabbitMQ
树
二叉排序树
平衡二叉排序树
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些
红黑树
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
红黑树的各类操作,左旋,右旋等都是比较固定的,参考
https://time.geekbang.org/column/article/68976
红黑树是一种平衡二叉查找树。它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。因为红黑树是一种性能非常稳定的二叉查找树,所以,在工程中,但凡是用到动态插入、删除、查找数据的场景,都可以用到它。不过,它实现起来比较复杂,如果自己写代码实现,难度会有些高,这个时候,我们其实更倾向用跳表来替代它。
跳表
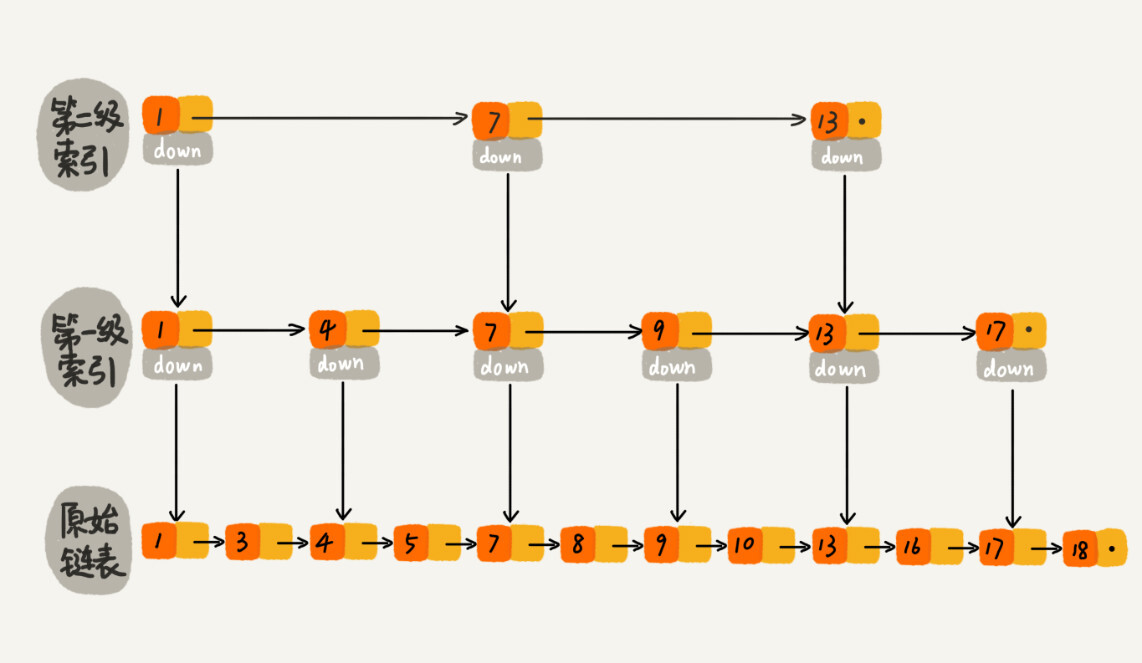
穷举算法
暴力法,通常是算法题上来的第一种想法
递归
Java 代码模版
public void recur(int level, int param) {
// terminator
if (level > MAX_LEVEL) {
// process result
return; }
// process current logic
process(level, param);
// drill down
recur( level: level + 1, newParam);
// restore current status
}贪心
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有 利)的选择,从而希望导致结果是全局最好或最优的算法。 贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不 能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行 选择,有回退功能。
动态规划
三个特征:最优子结构、无后效性和重复子问题
1.定义状态
2.列状态转移方程
3.根据状态转移方程编写实现
遗传算法
需要后续详细的研究一下
网络
一个url从输入到页面展现的流程
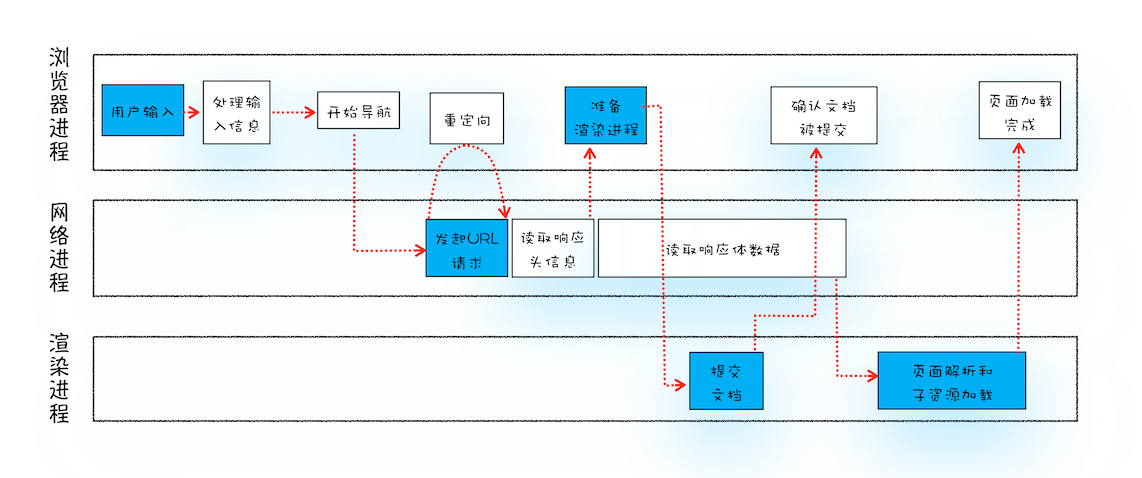
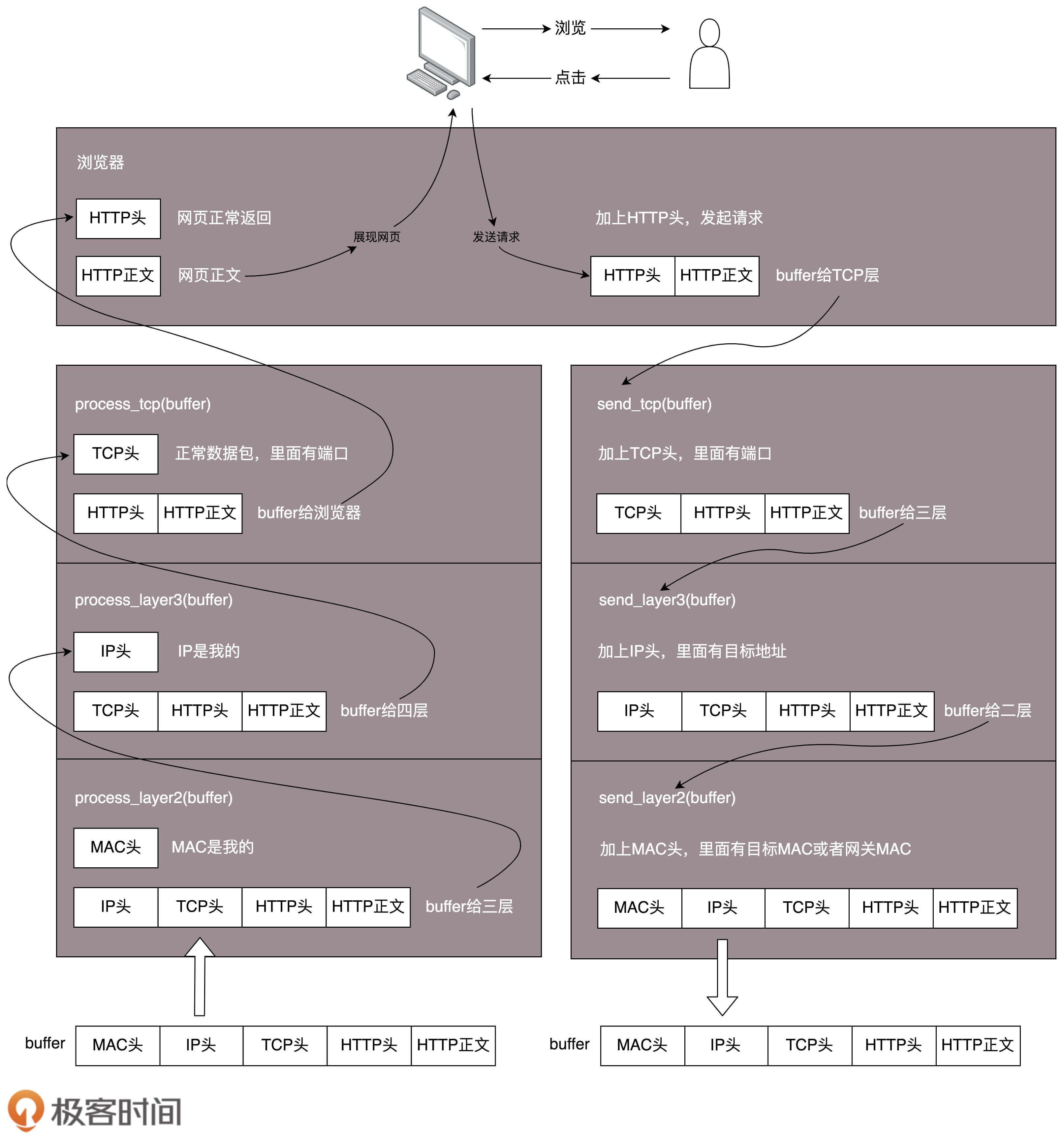
osi7层模型,tcp/ip四层模型
三次握手
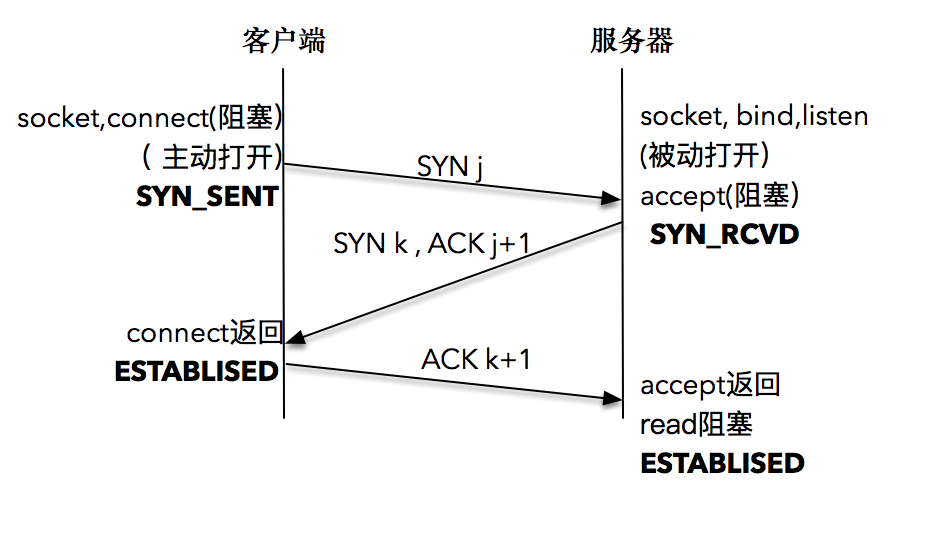
客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 j,客户端进入 SYNC_SENT 状态;
服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 j+1,表示对 SYN 包 j 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 k,服务器端进入 SYNC_RCVD 状态;
客户端协议栈收到 ACK 之后,使得应用程序从 connect 调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 k+1;
应答包到达服务器端后,服务器端协议栈使得 accept 阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
四层挥手

首先,一方应用程序调用 close,我们称该方为主动关闭方,该端的 TCP 发送一个 FIN 包,表示需要关闭连接。之后主动关闭方进入 FIN_WAIT_1 状态。接着,接收到这个 FIN 包的对端执行被动关闭。这个 FIN 由 TCP 协议栈处理,我们知道,TCP 协议栈为 FIN 包插入一个文件结束符 EOF 到接收缓冲区中,应用程序可以通过 read 调用来感知这个 FIN 包。一定要注意,这个 EOF 会被放在已排队等候的其他已接收的数据之后,这就意味着接收端应用程序需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,被动关闭方进入 CLOSE_WAIT 状态。接下来,被动关闭方将读到这个 EOF,于是,应用程序也调用 close 关闭它的套接字,这导致它的 TCP 也发送一个 FIN 包。这样,被动关闭方将进入 LAST_ACK 状态。最终,主动关闭方接收到对方的 FIN 包,并确认这个 FIN 包。主动关闭方进入 TIME_WAIT 状态,而接收到 ACK 的被动关闭方则进入 CLOSED 状态。经过 2MSL 时间之后,主动关闭方也进入 CLOSED 状态。
http
- 7种方法
- 5种状态
- 协议版本
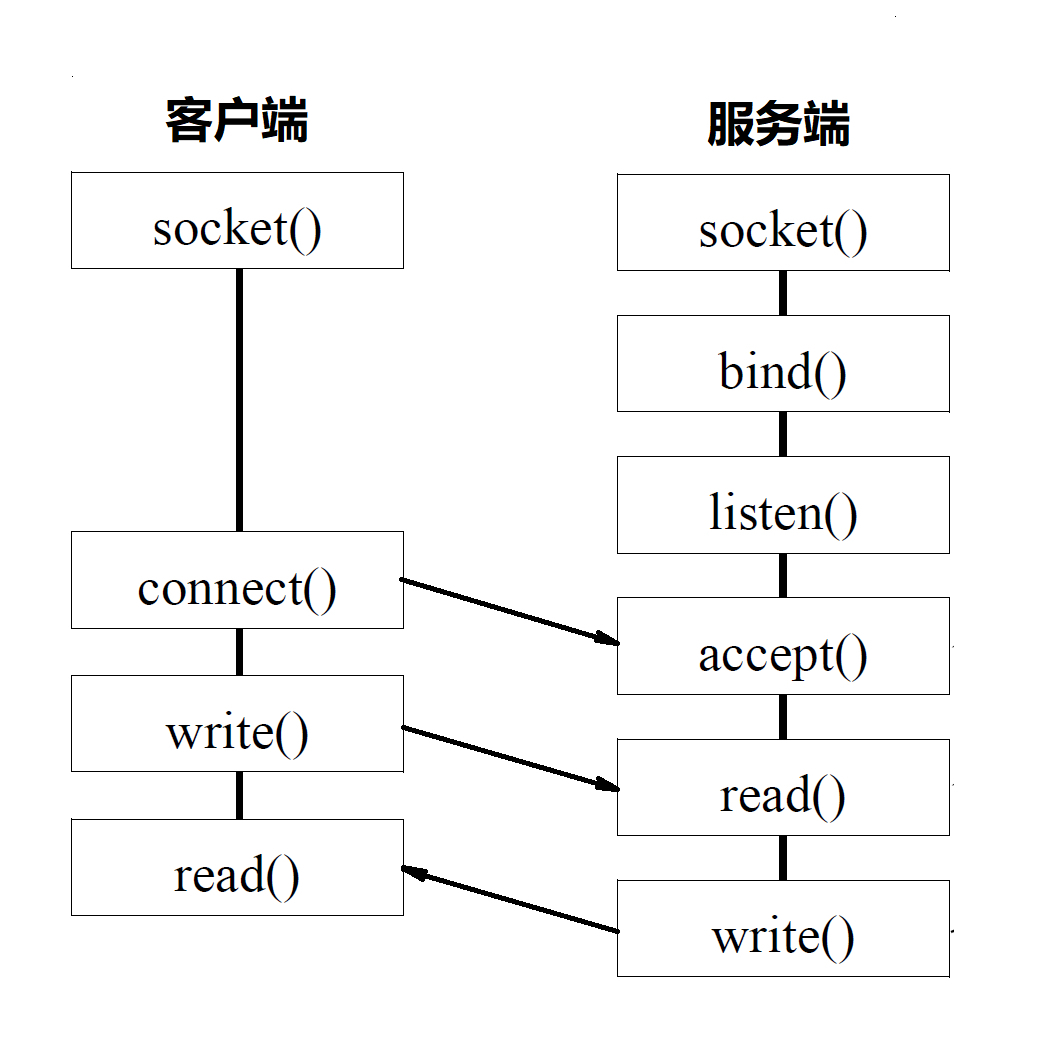
基于tcp的socket函数调用过程
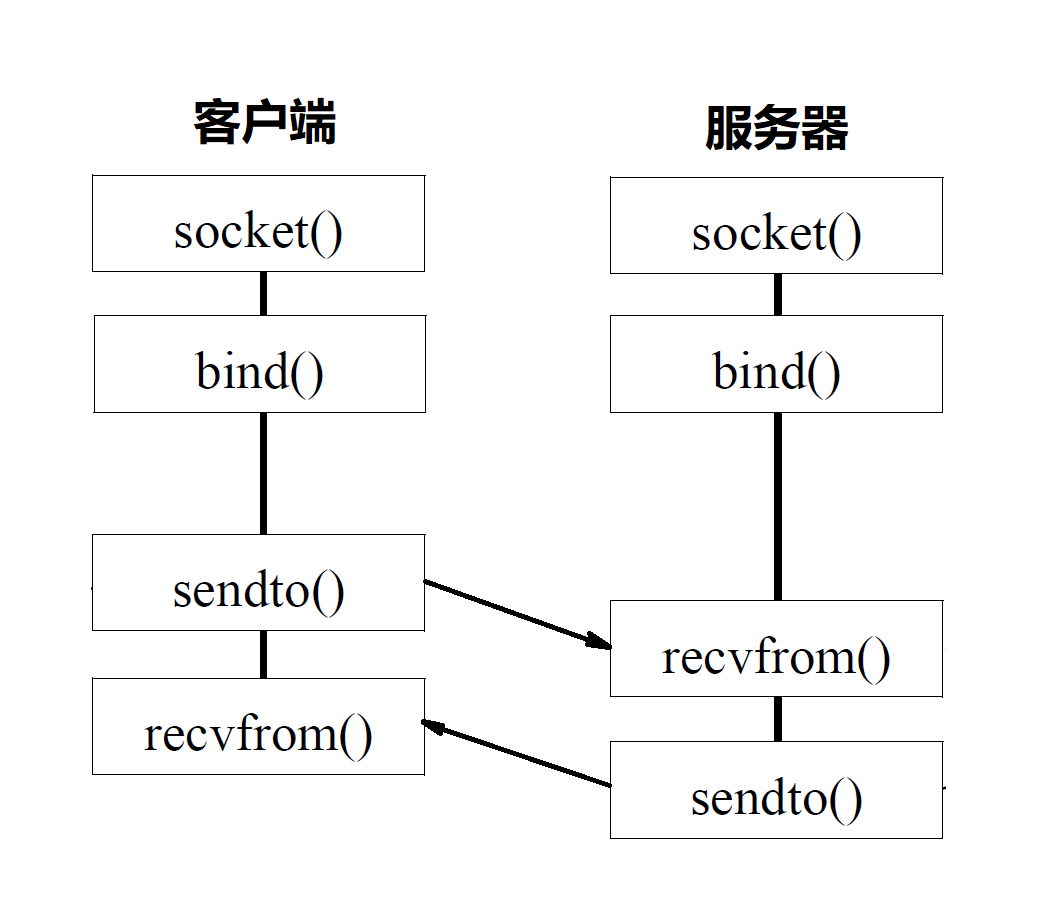
基于UDP的函数调用过程
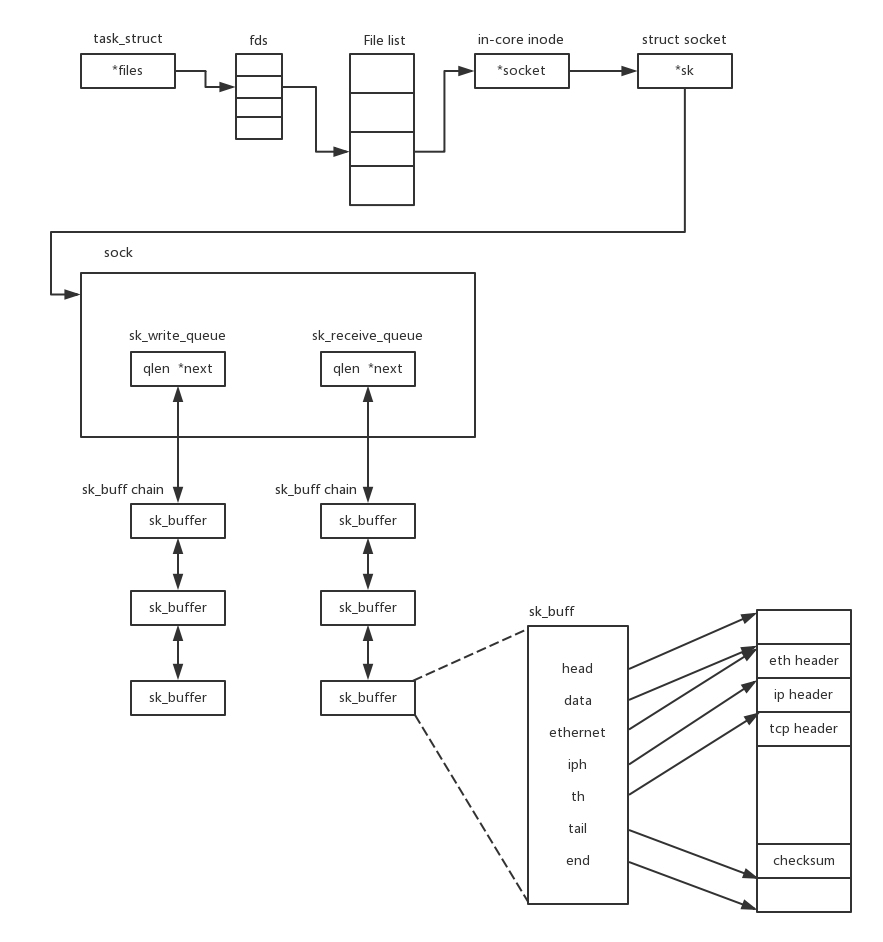
socket的数据结构
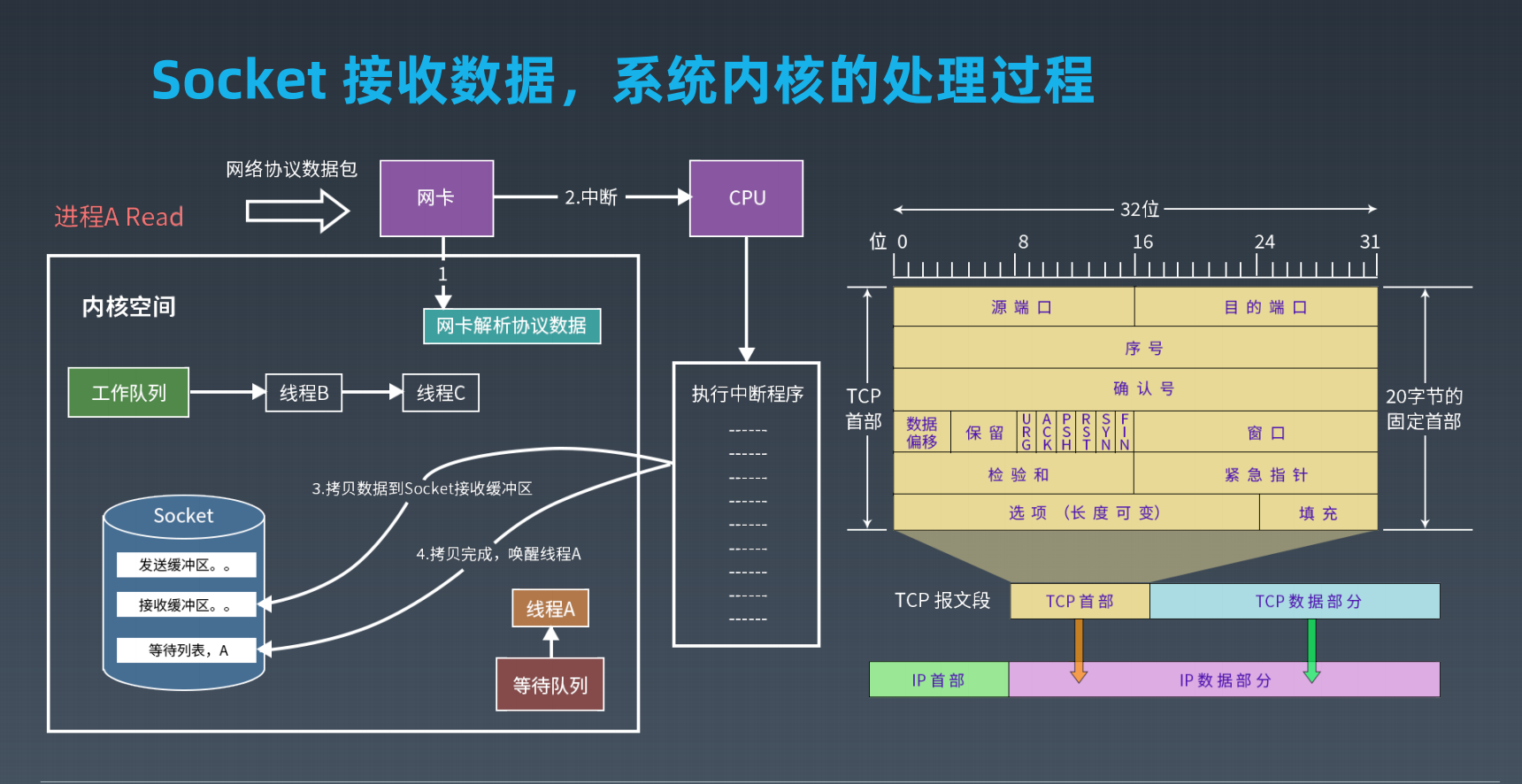
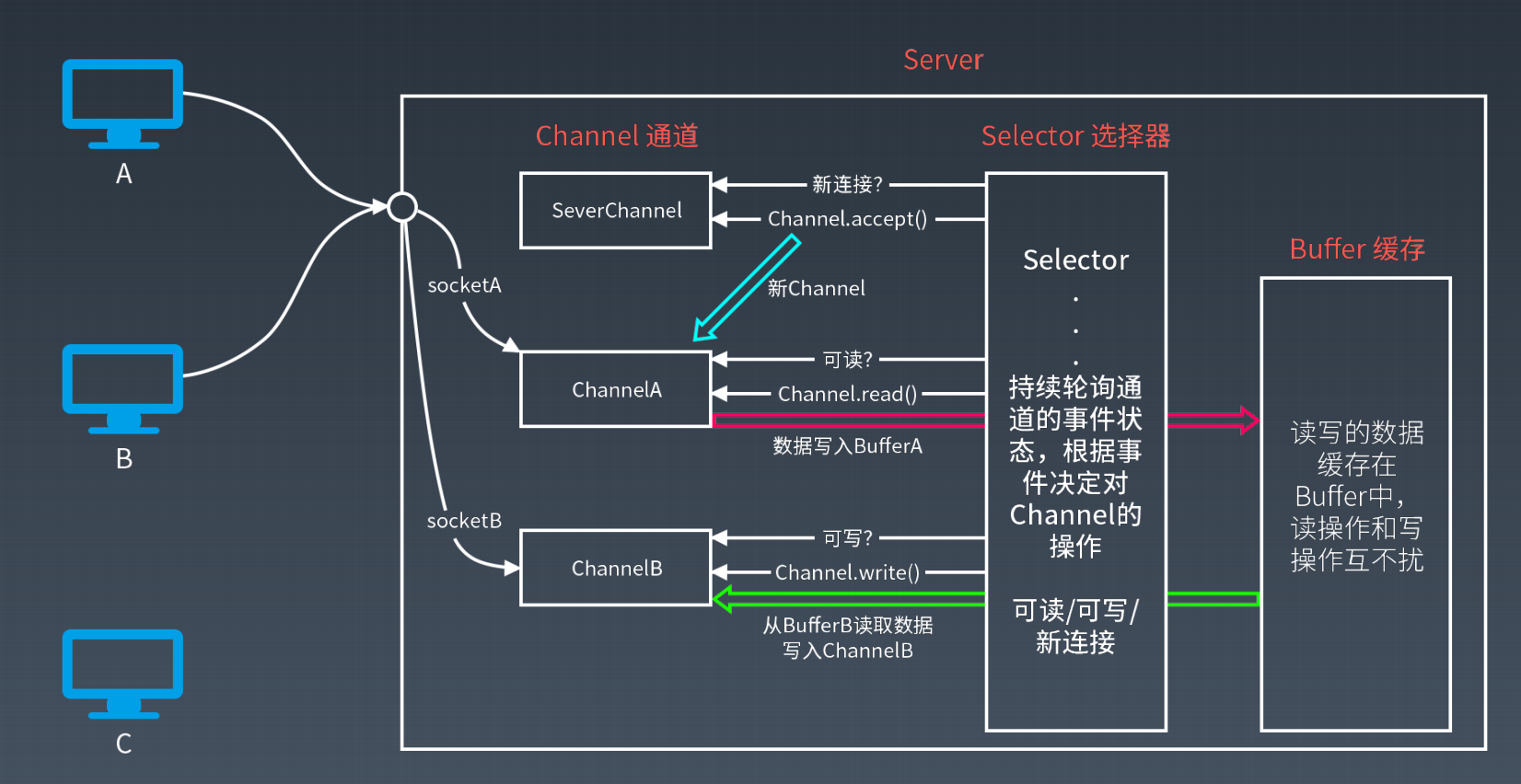
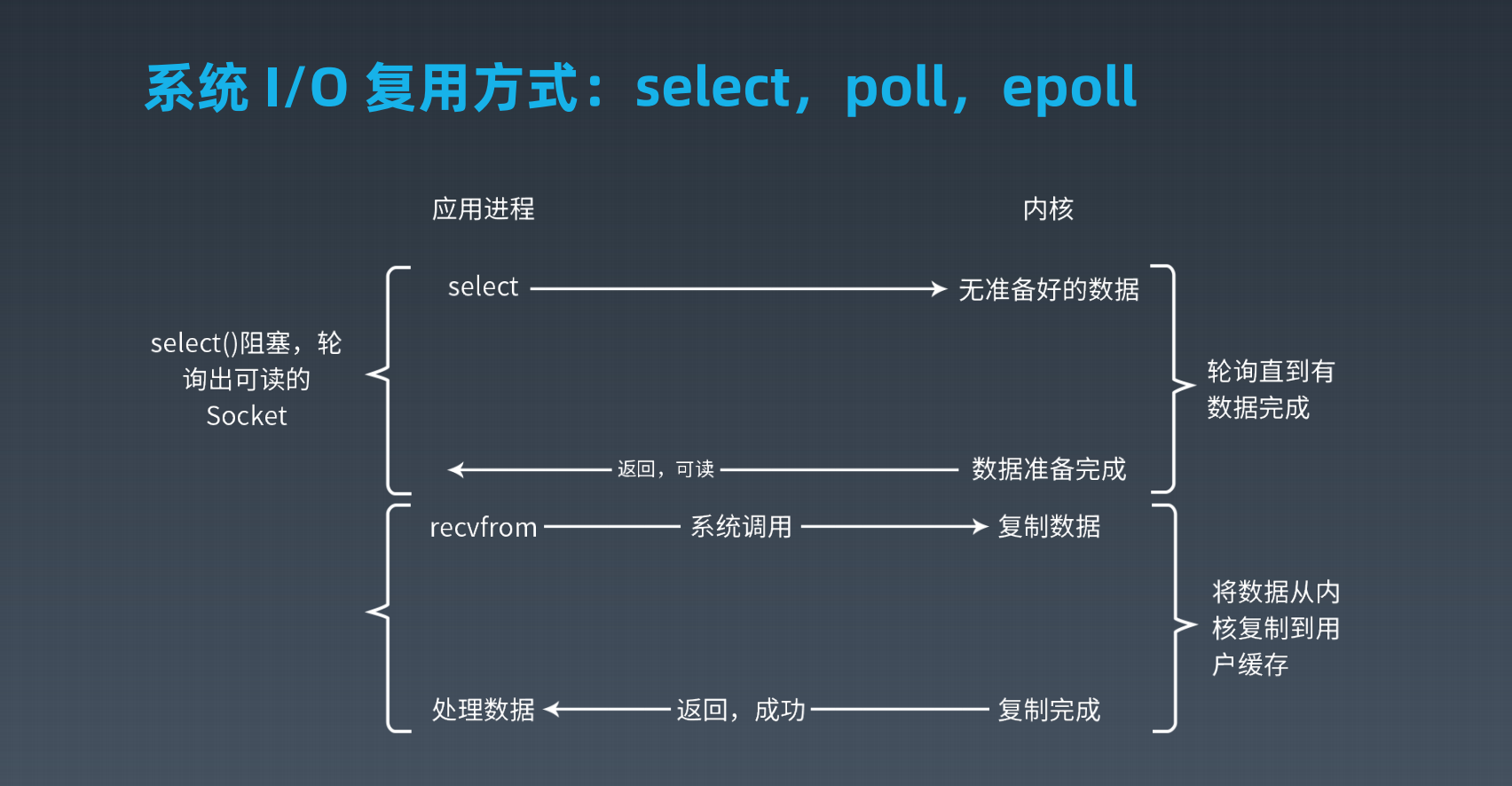
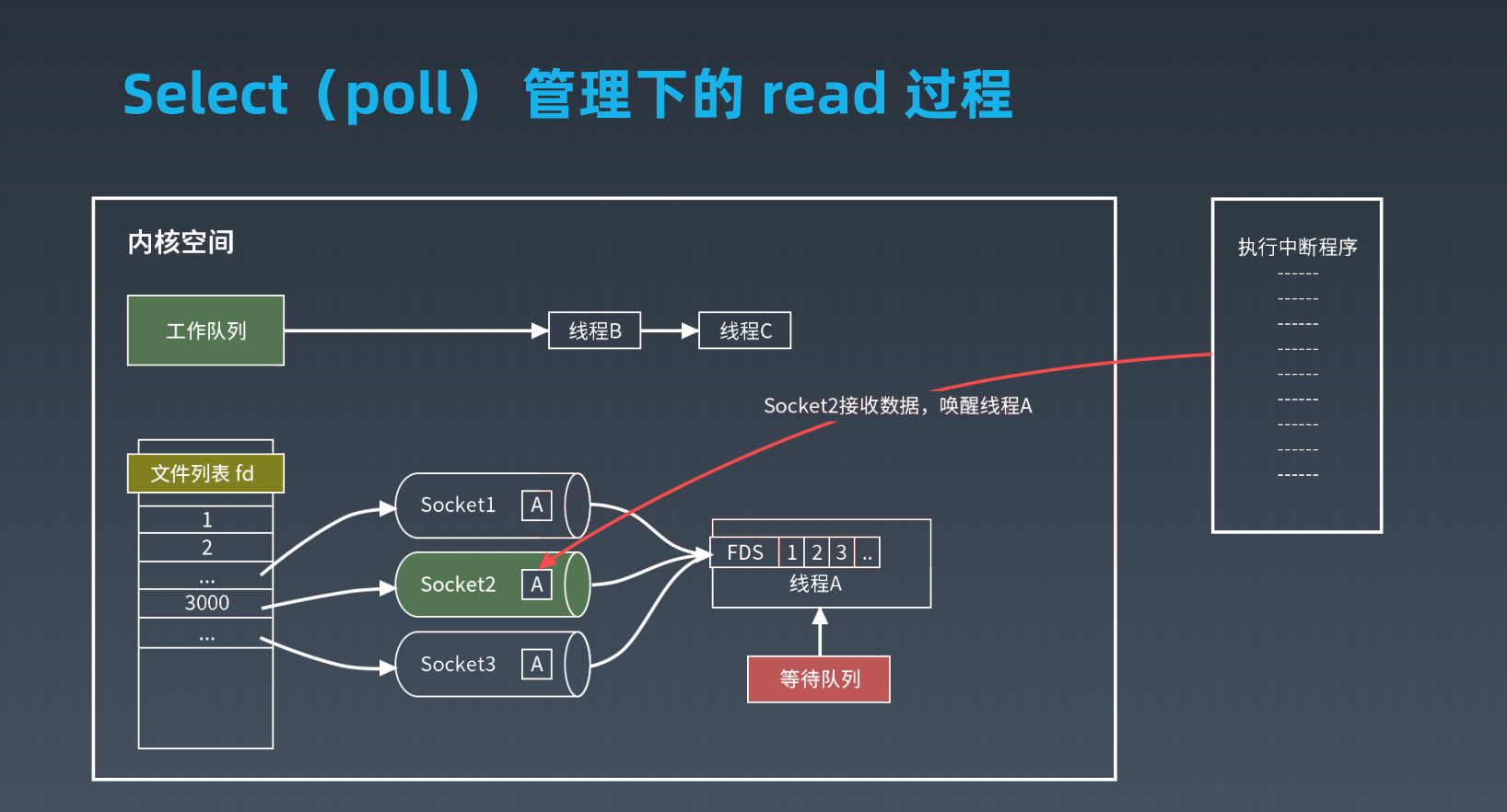
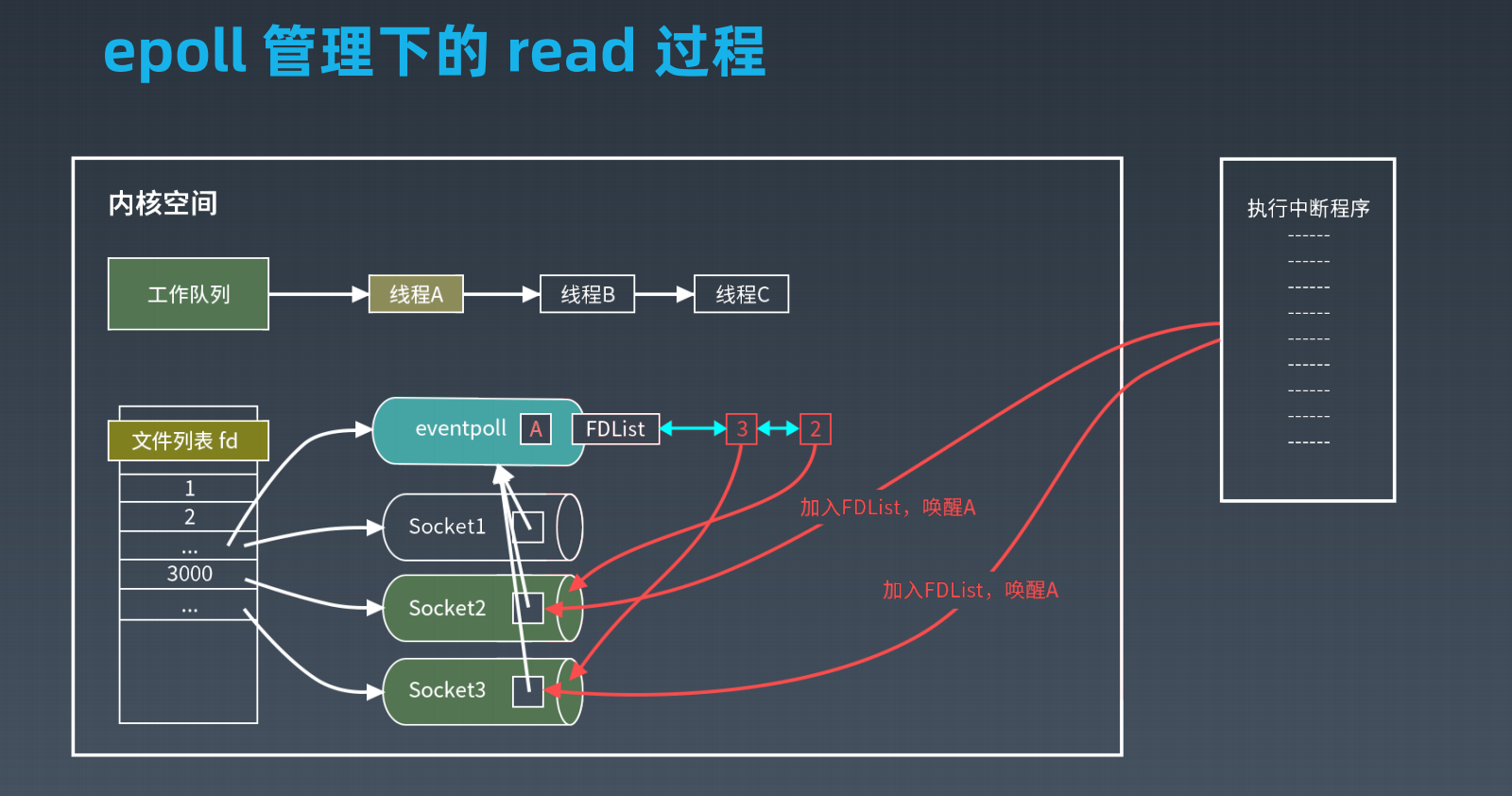
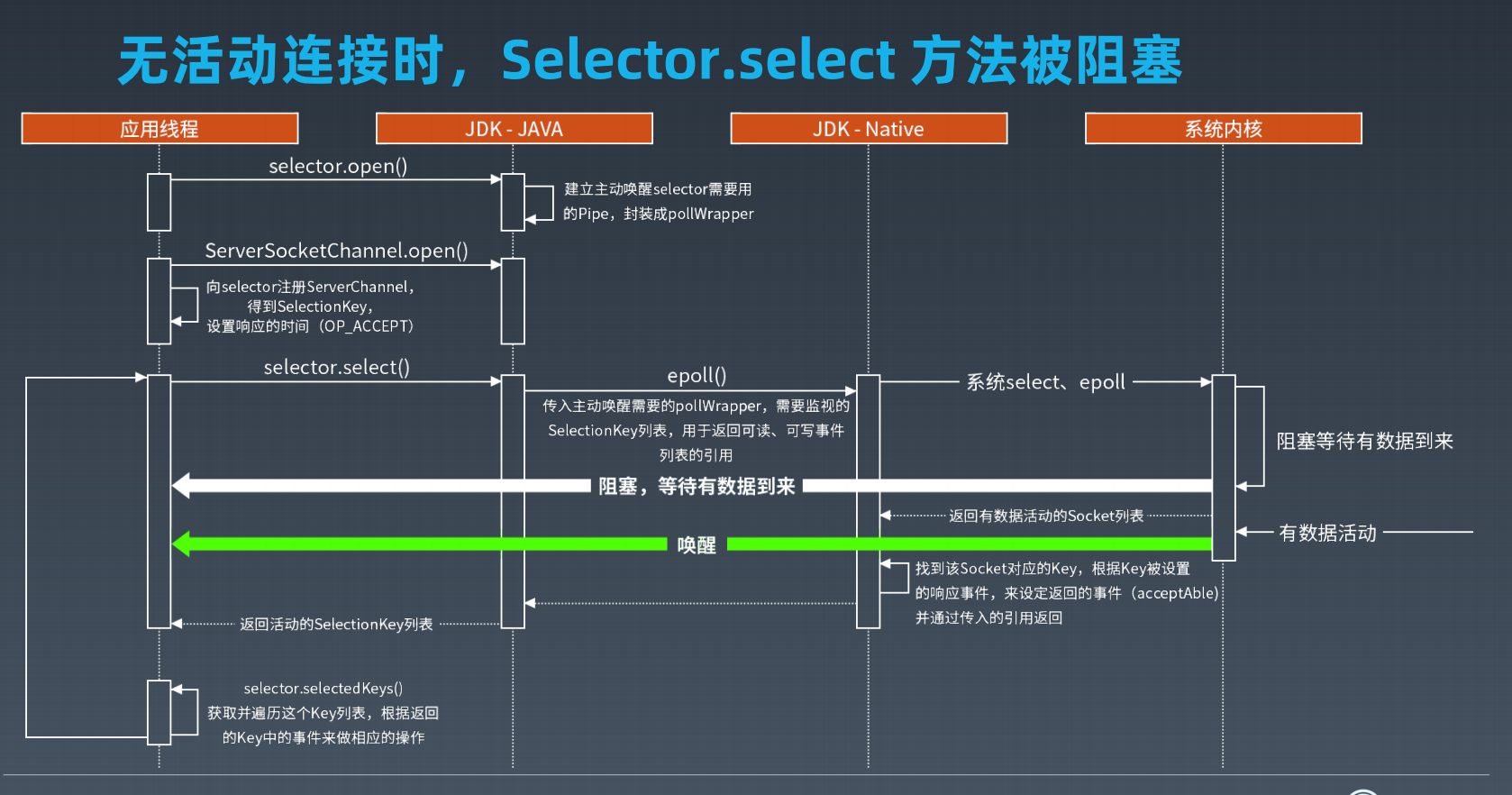
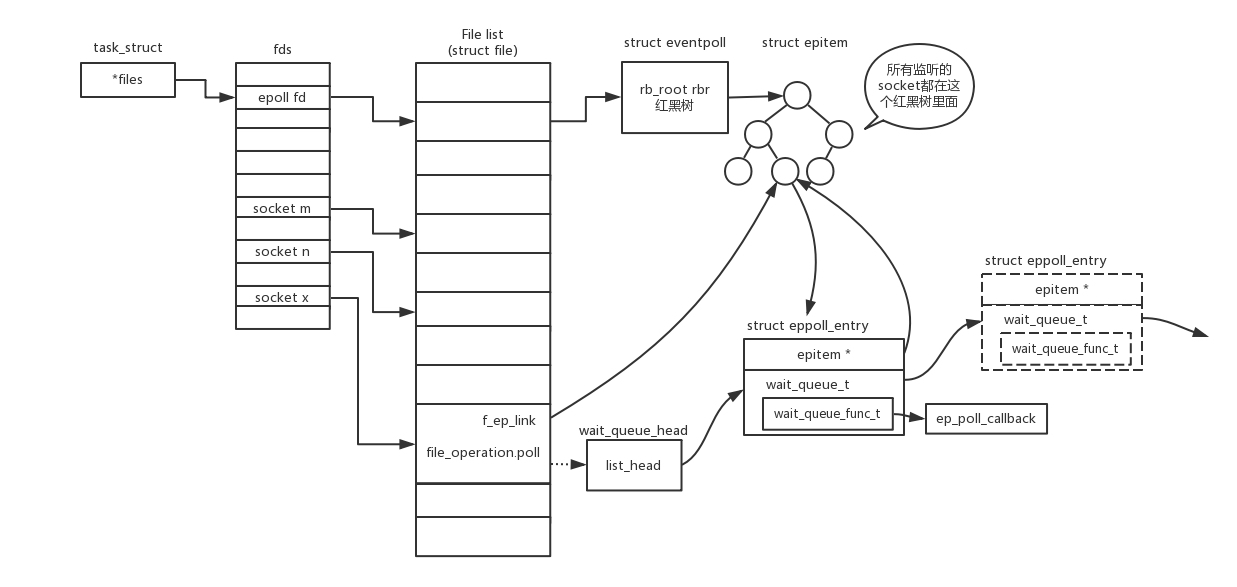
epoll
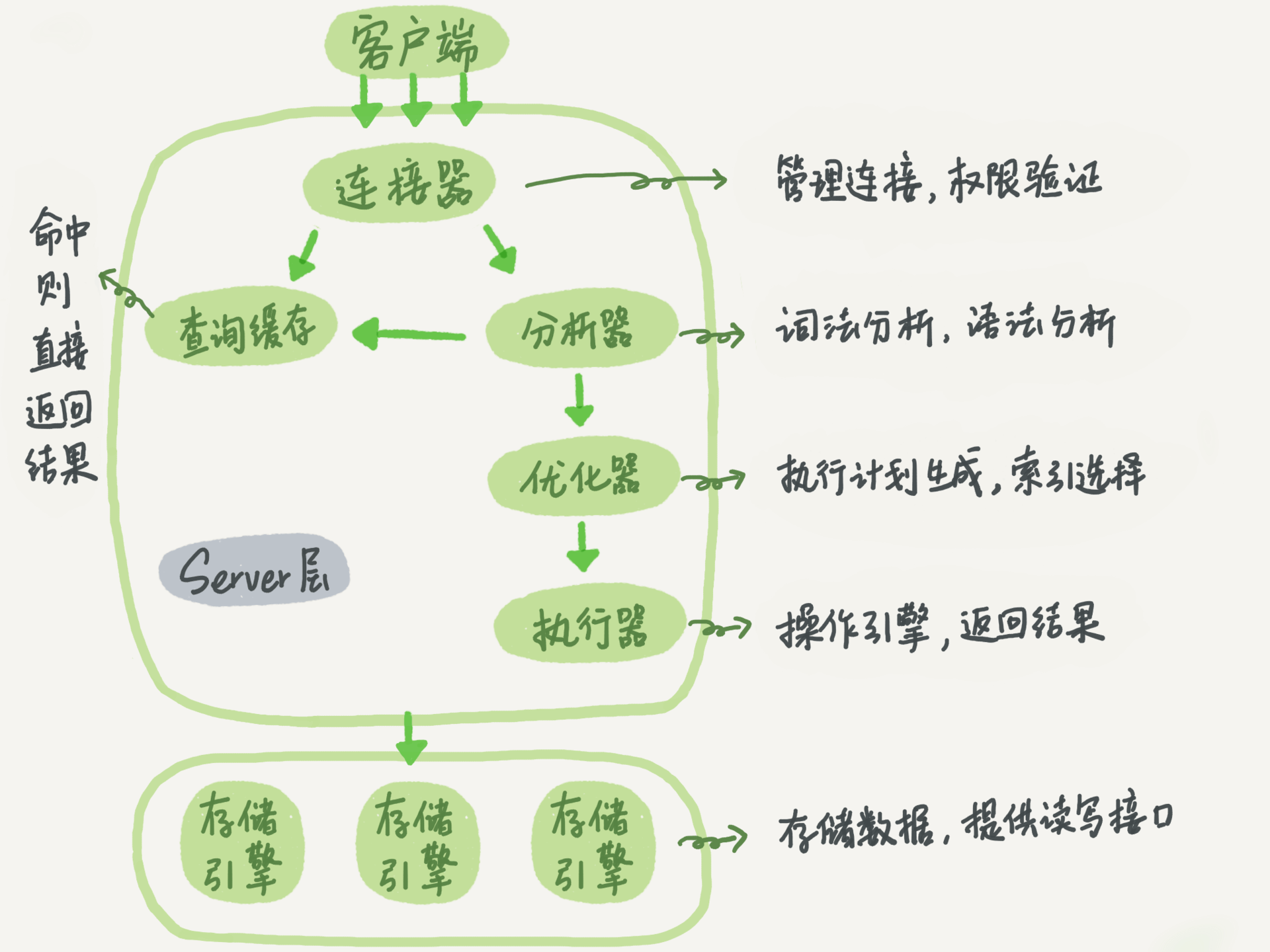
数据库原理和性能优化
索引
- B+索引
- 聚簇索引
事务ACID
执行计划