大数据整体概览

HDFS
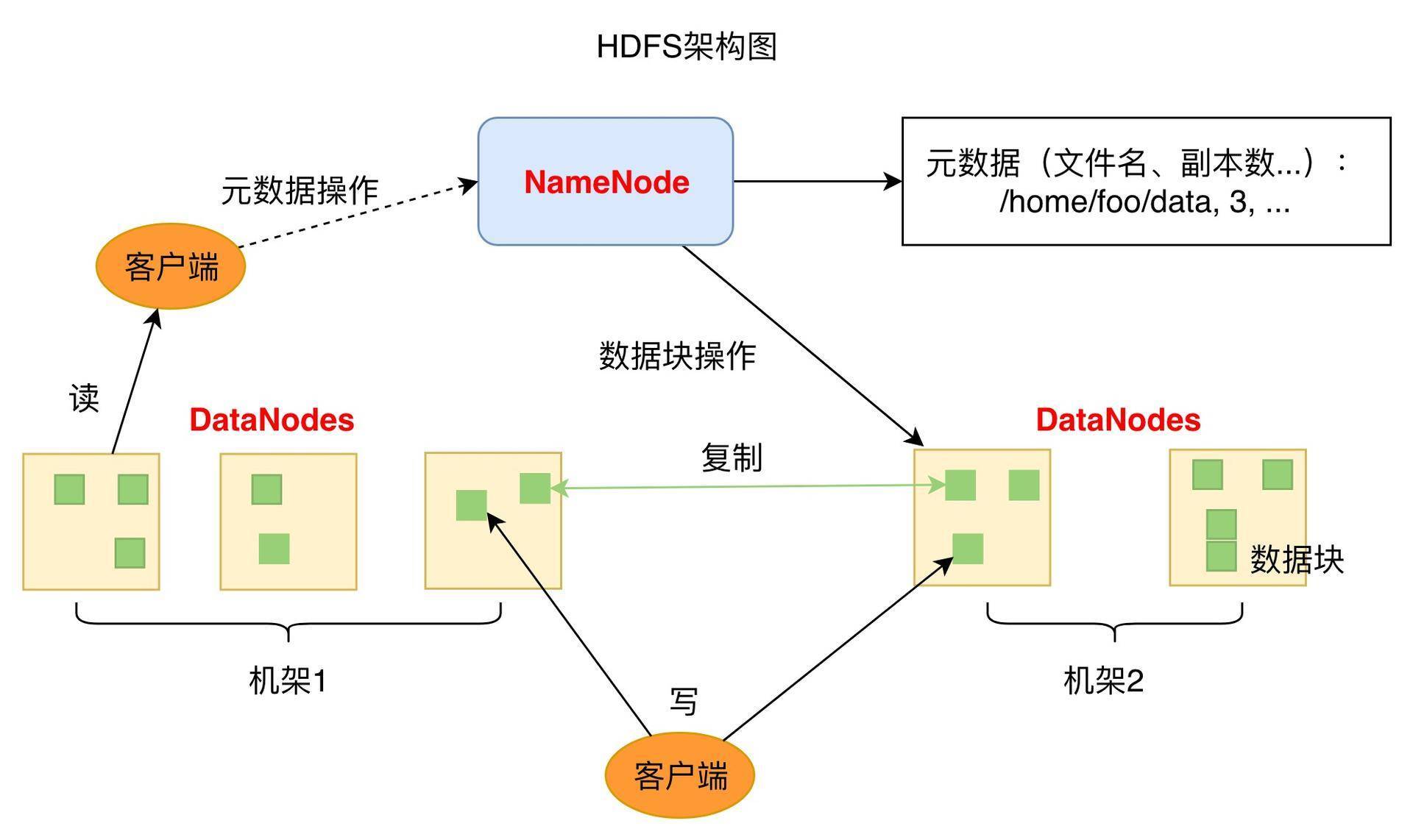
数据存储

高可用
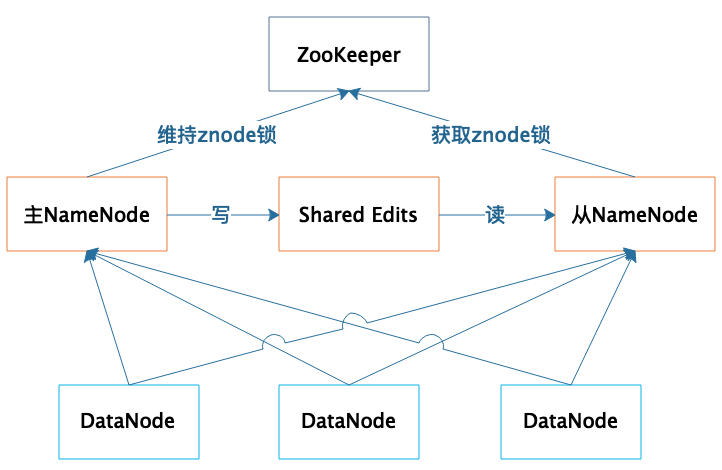
集群部署两台 NameNode 服务器,一台作为主服务器提供服务,一台作为从服务器进行热备,两台服务器通过 ZooKeeper 选举,主要是通过争夺 znode 锁资源,决定谁是主服务器。而 DataNode 则会向两个 NameNode 同时发送心跳数据,但是只有主 NameNode 才能向 DataNode 返回控制信息。正常运行期间,主从 NameNode 之间通过一个共享存储系统 shared edits 来同步文件系统的元数据信息。当主 NameNode 服务器宕机,从 NameNode 会通过 ZooKeeper 升级成为主服务器,并保证 HDFS 集群的元数据信息,也就是文件分配表信息完整一致。
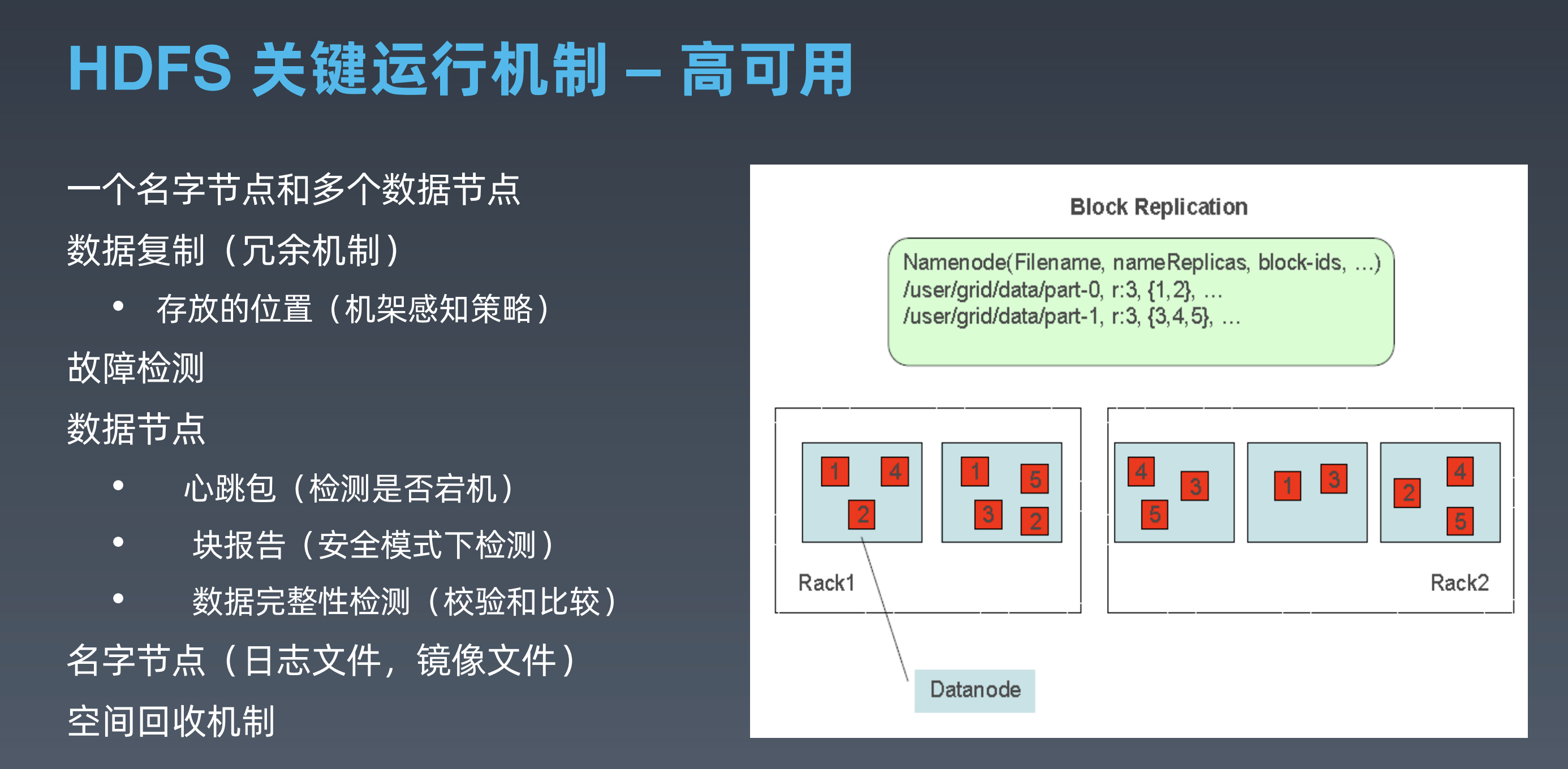
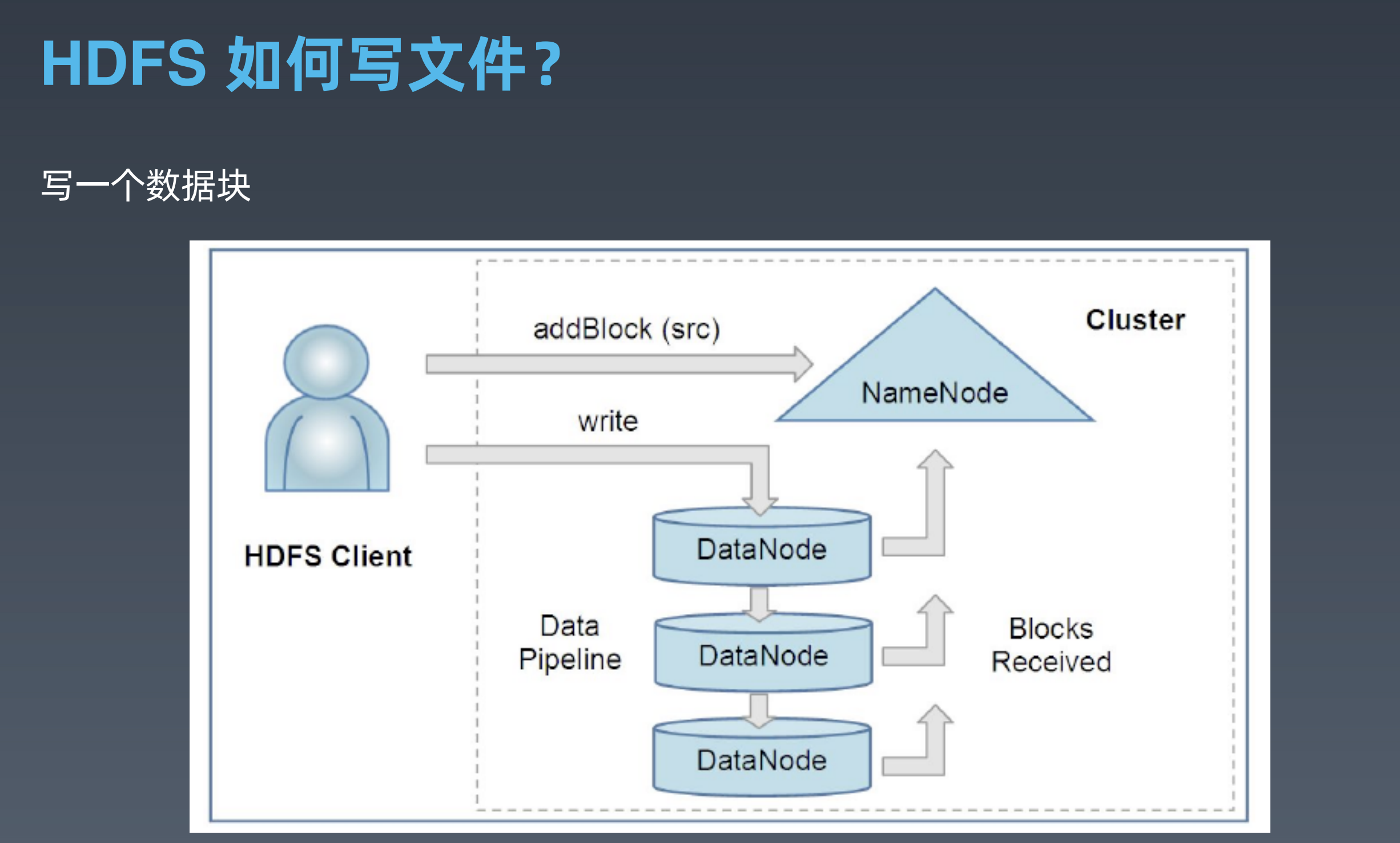
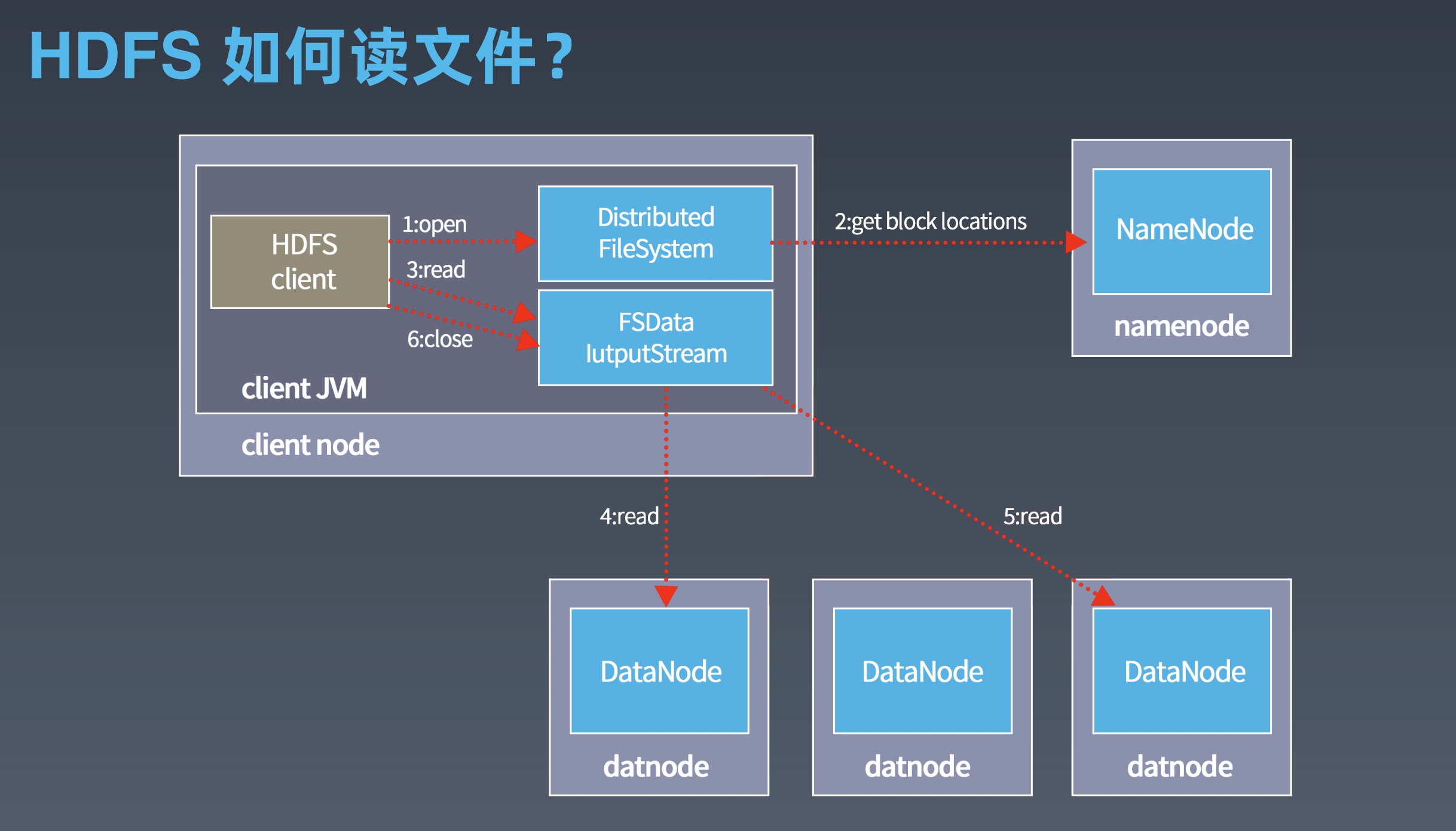
HDFS的基本操作





MapReduce
MapReduce 既是一个编程模型,又是一个计算框架
MapReduce1.0的过程
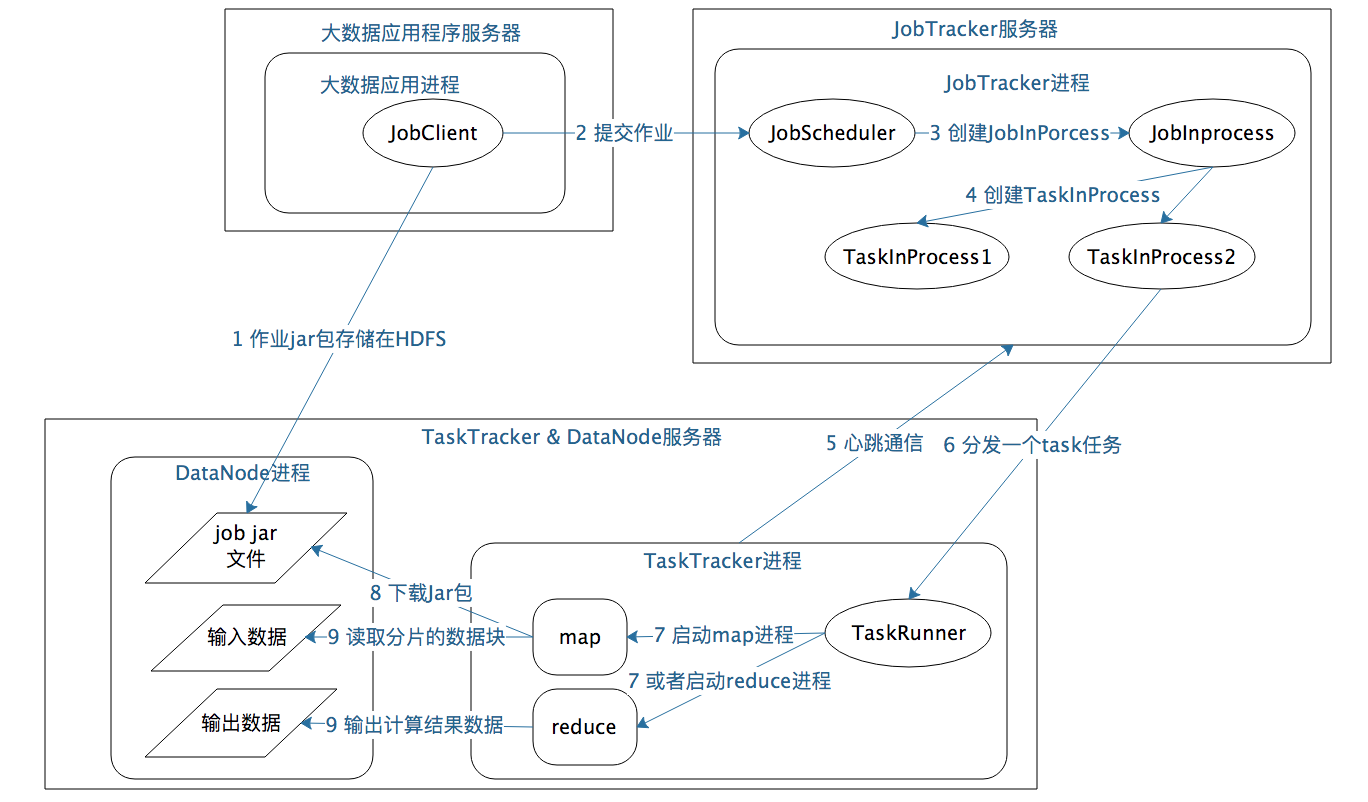
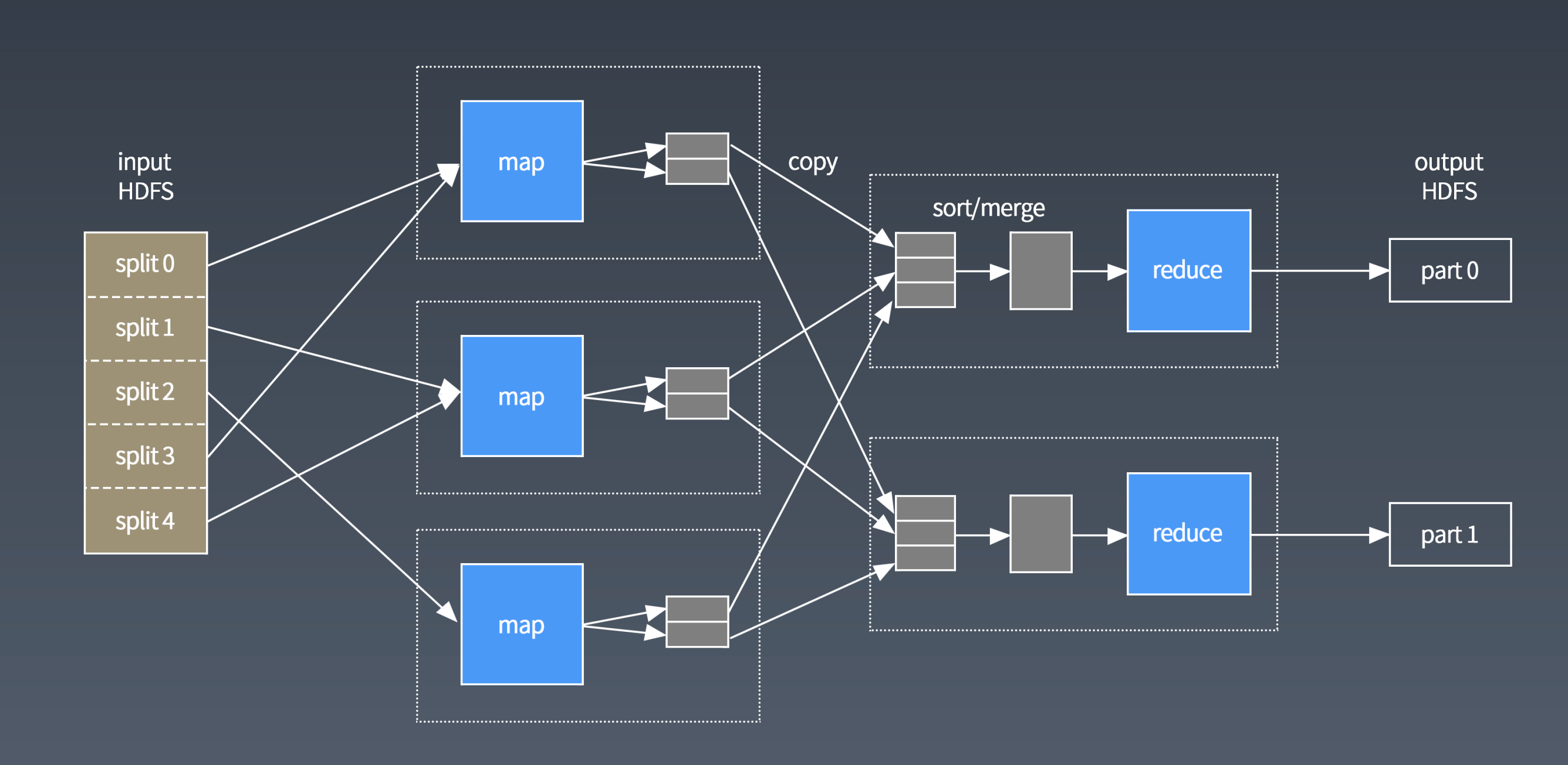
1.应用进程 JobClient 将用户作业 JAR 包存储在 HDFS 中,将来这些 JAR 包会分发给 Hadoop 集群中的服务器执行 MapReduce 计算。
2. 应用程序提交 job 作业给 JobTracker。
3.JobTracker 根据作业调度策略创建 JobInProcess 树,每个作业都会有一个自己的 JobInProcess 树。
4.JobInProcess 根据输入数据分片数目(通常情况就是数据块的数目)和设置的 Reduce 数目创建相应数量的 TaskInProcess。
5.TaskTracker 进程和 JobTracker 进程进行定时通信。
6. 如果 TaskTracker 有空闲的计算资源(有空闲 CPU 核心),JobTracker 就会给它分配任务。分配任务的时候会根据 TaskTracker 的服务器名字匹配在同一台机器上的数据块计算任务给它,使启动的计算任务正好处理本机上的数据,以实现我们一开始就提到的“移动计算比移动数据更划算”。
7.TaskTracker 收到任务后根据任务类型(是 Map 还是 Reduce)和任务参数(作业 JAR 包路径、输入数据文件路径、要处理的数据在文件中的起始位置和偏移量、数据块多个备份的 DataNode 主机名等),启动相应的 Map 或者 Reduce 进程。
8.Map 或者 Reduce 进程启动后,检查本地是否有要执行任务的 JAR 包文件,如果没有,就去 HDFS 上下载,然后加载 Map 或者 Reduce 代码开始执行。
9. 如果是 Map 进程,从 HDFS 读取数据(通常要读取的数据块正好存储在本机);如果是 Reduce 进程,将结果数据写出到 HDFS。
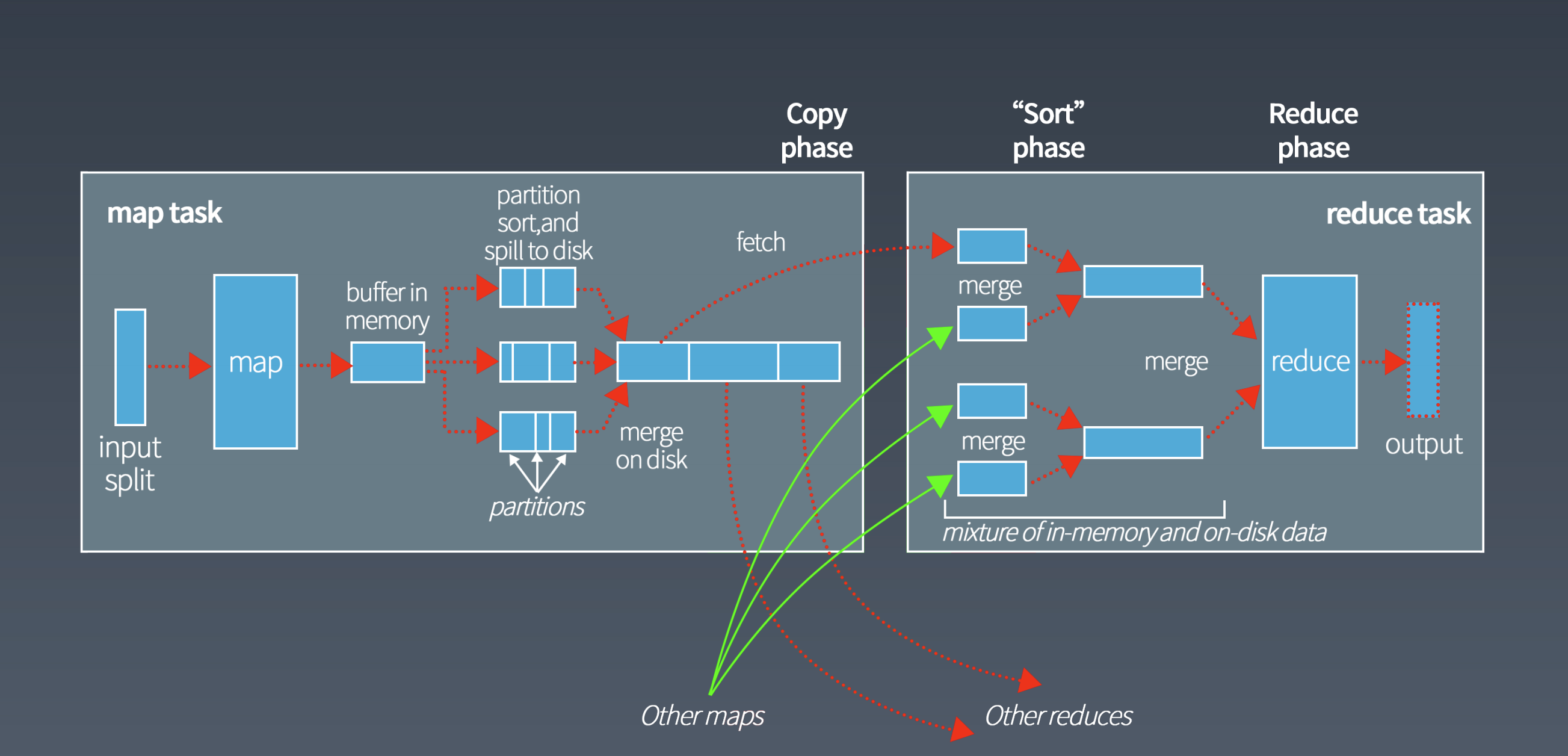
shuffle
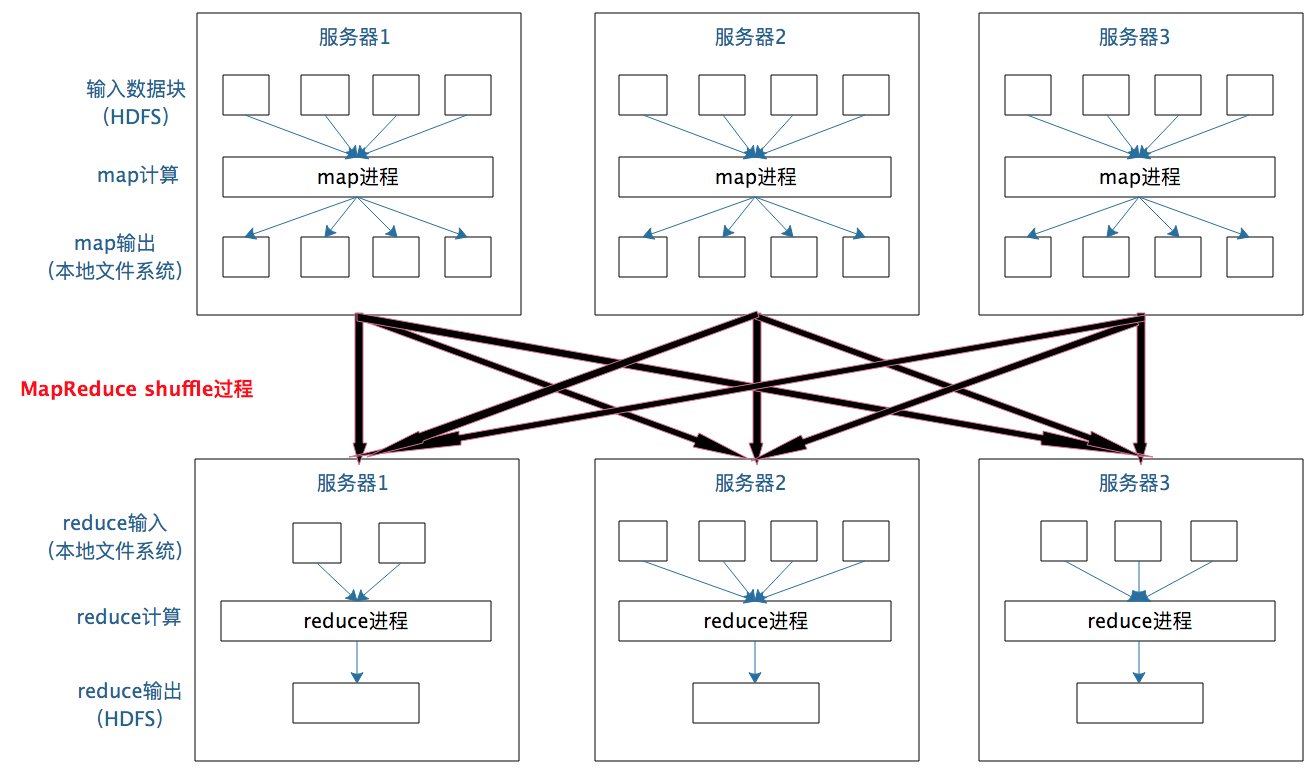
shuffle 是大数据计算过程中最神奇的地方,不管是 MapReduce 还是 Spark,只要是大数据批处理计算,一定都会有 shuffle 过程,只有让数据关联起来,数据的内在关系和价值才会呈现出来。shuffle 也是整个 MapReduce 过程中最难、最消耗性能的地方,在 MapReduce 早期代码中,一半代码都是关于 shuffle 处理的。
YARN
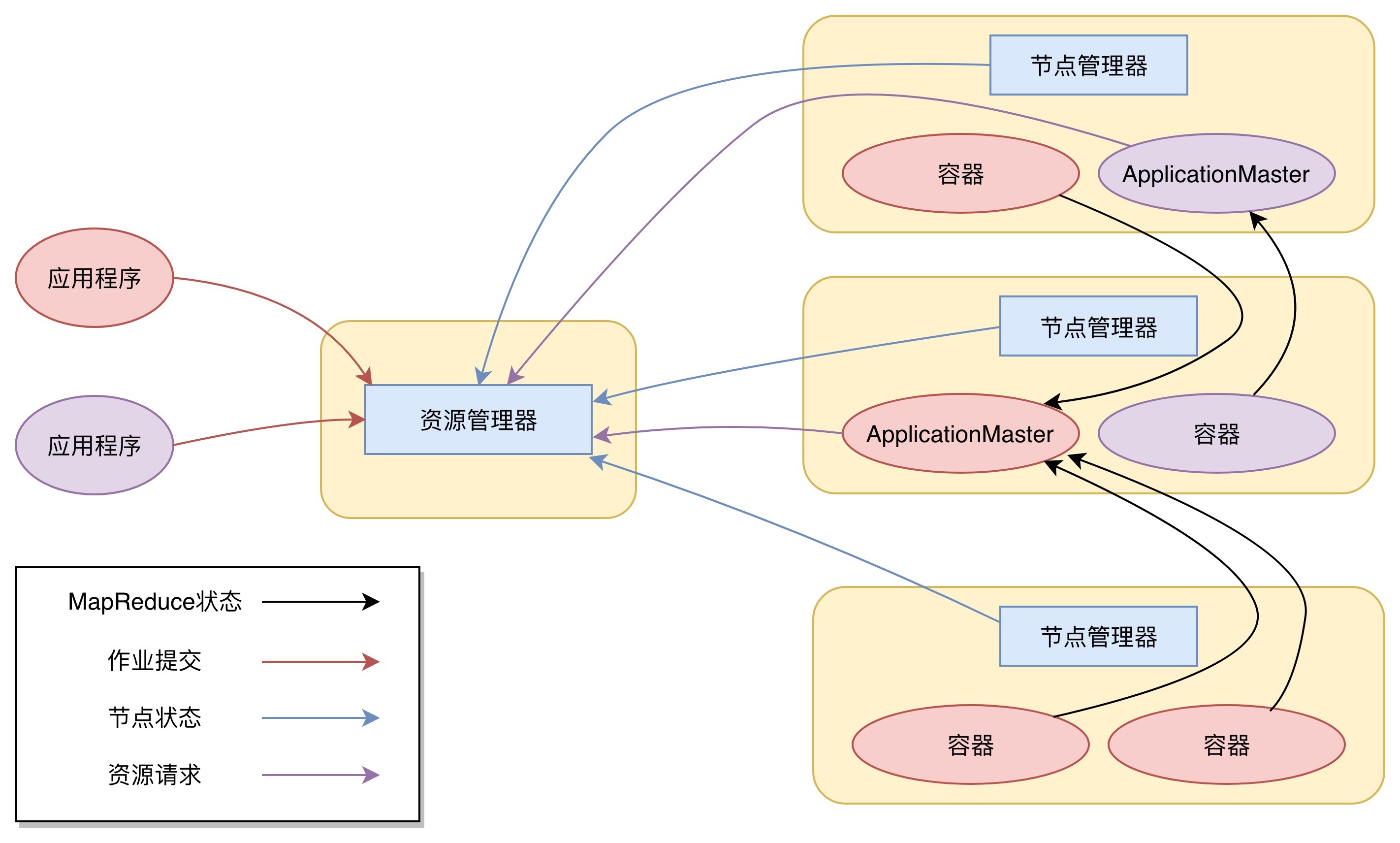
Yarn 包括两个部分:一个是资源管理器(Resource Manager),一个是节点管理器(Node Manager)。这也是 Yarn 的两种主要进程:ResourceManager 进程负责整个集群的资源调度管理,通常部署在独立的服务器上;NodeManager 进程负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,基本上跟 HDFS 的 DataNode 进程一起出现。
资源管理器又包括两个主要组件:调度器和应用程序管理器。调度器其实就是一个资源分配算法,根据应用程序(Client)提交的资源申请和当前服务器集群的资源状况进行资源分配。Yarn 内置了几种资源调度算法,包括 Fair Scheduler、Capacity Scheduler 等,你也可以开发自己的资源调度算法供 Yarn 调用。Yarn 进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU 等计算资源,默认配置下,每个容器包含一个 CPU 核心。容器由 NodeManager 进程启动和管理,NodeManger 进程会监控本节点上容器的运行状况并向 ResourceManger 进程汇报。应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个 ApplicationMaster,ApplicationMaster 也需要运行在容器里面。每个应用程序启动后都会先启动自己的 ApplicationMaster,由 ApplicationMaster 根据应用程序的资源需求进一步向 ResourceManager 进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
Yarn 的整个工作流程:
1. 我们向 Yarn 提交应用程序,包括 MapReduce ApplicationMaster、我们的 MapReduce 程序,以及 MapReduce Application 启动命令。
2.ResourceManager 进程和 NodeManager 进程通信,根据集群资源,为用户程序分配第一个容器,并将 MapReduce ApplicationMaster 分发到这个容器上面,并在容器里面启动 MapReduce ApplicationMaster。
3.MapReduce ApplicationMaster 启动后立即向 ResourceManager 进程注册,并为自己的应用程序申请容器资源。
4.MapReduce ApplicationMaster 申请到需要的容器后,立即和相应的 NodeManager 进程通信,将用户 MapReduce 程序分发到 NodeManager 进程所在服务器,并在容器中运行,运行的就是 Map 或者 Reduce 任务。
5.Map 或者 Reduce 任务在运行期和 MapReduce ApplicationMaster 通信,汇报自己的运行状态,如果运行结束,MapReduce ApplicationMaster 向 ResourceManager 进程注销并释放所有的容器资源。
HIVE
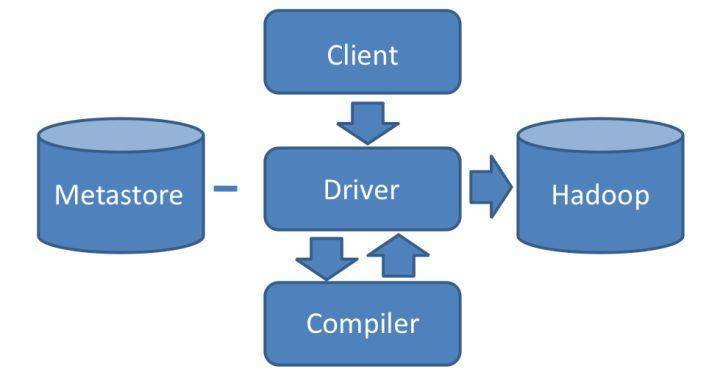
通过 Hive 的 Client(Hive 的命令行工具,JDBC 等)向 Hive 提交 SQL 命令。如果是创建数据表的 DDL(数据定义语言),Hive 就会通过执行引擎 Driver 将数据表的信息记录在 Metastore 元数据组件中,这个组件通常用一个关系数据库实现,记录表名、字段名、字段类型、关联 HDFS 文件路径等这些数据库的 Meta 信息(元信息)。如果我们提交的是查询分析数据的 DQL(数据查询语句),Driver 就会将该语句提交给自己的编译器 Compiler 进行语法分析、语法解析、语法优化等一系列操作,最后生成一个 MapReduce 执行计划。然后根据执行计划生成一个 MapReduce 的作业,提交给 Hadoop MapReduce 计算框架处理。