你所在的行业常用的数据分析指标有哪些
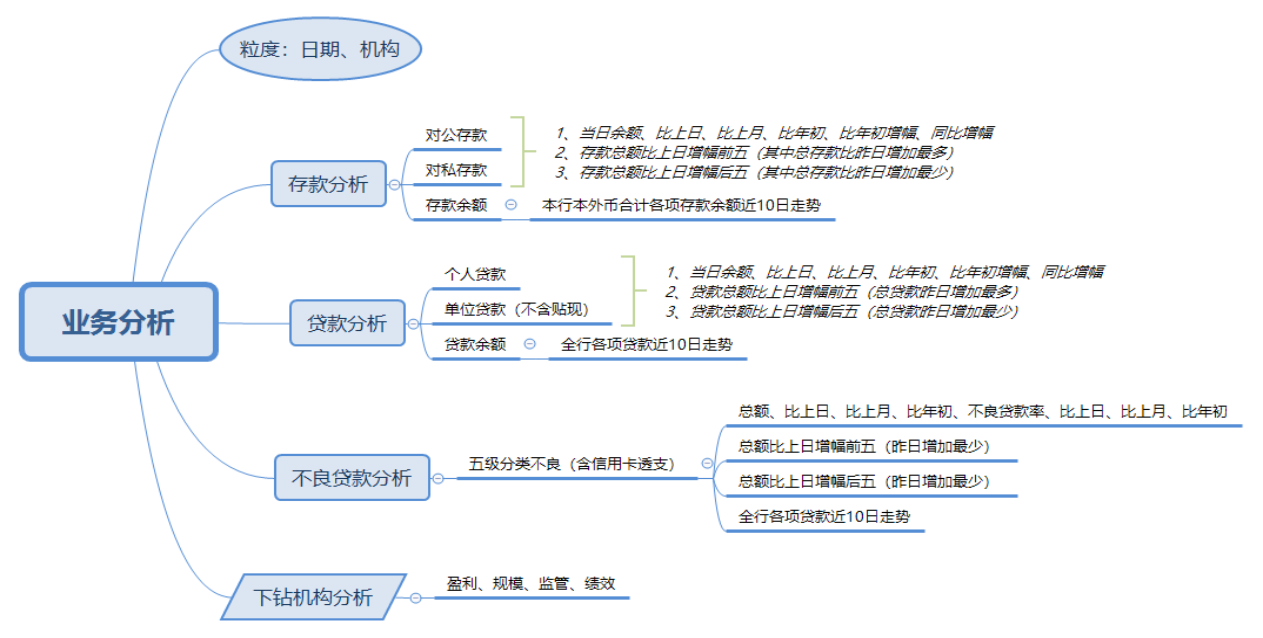
作者所在的银行业,每天都会产生非常多的报表以及相关的指标分析,以最常见的存款、贷款数据分类,可以参考下面的这个图:
google搜索引擎是如何对搜索引擎排序的?(描述PageRank算法)
PageRank算法通过网页的超链接关系来确定一个页面的等级。google把A页面到B页面的链接解释为A页面给B页面投票,google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级,一个高等级的页面会使其他低等级的页面等级提升。
一个页面的得票数由所有链接到它的页面的重要性来决定,到一个页面的超链接相当于给该页面投一票。一个页面的PageRank由所有链向它的页面(入链)的重要性经过递归算法得到。一个较多入链的页面会有较高的等级,相反如果一个页面没有任何入链,那么它没有等级。
PageRank算法中有两个概念:出链指的是链接出去的链接。入链指的是链接进来的链接。一个网页的影响力 = 所有入链集合的页面的加权影响力之和,用公式表示为:
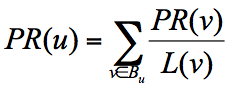
u 为待评估的页面,Bu 为页面 u 的入链集合。针对入链集合中的任意页面 v,它能给 u 带来的影响力是其自身的影响力 PR(v) 除以 v 页面的出链数量,即页面 v 把影响力 PR(v) 平均分配给了它的出链,这样统计所有能给 u 带来链接的页面 v,得到的总和就是网页 u 的影响力,即为 PR(u)。所以,出链会给被链接的页面赋予影响力,当我们统计了一个网页链出去的数量,也就是统计了这个网页的跳转概率。
假设一共有 4 个网页 A、B、C、D。它们之间的链接信息如图所示:
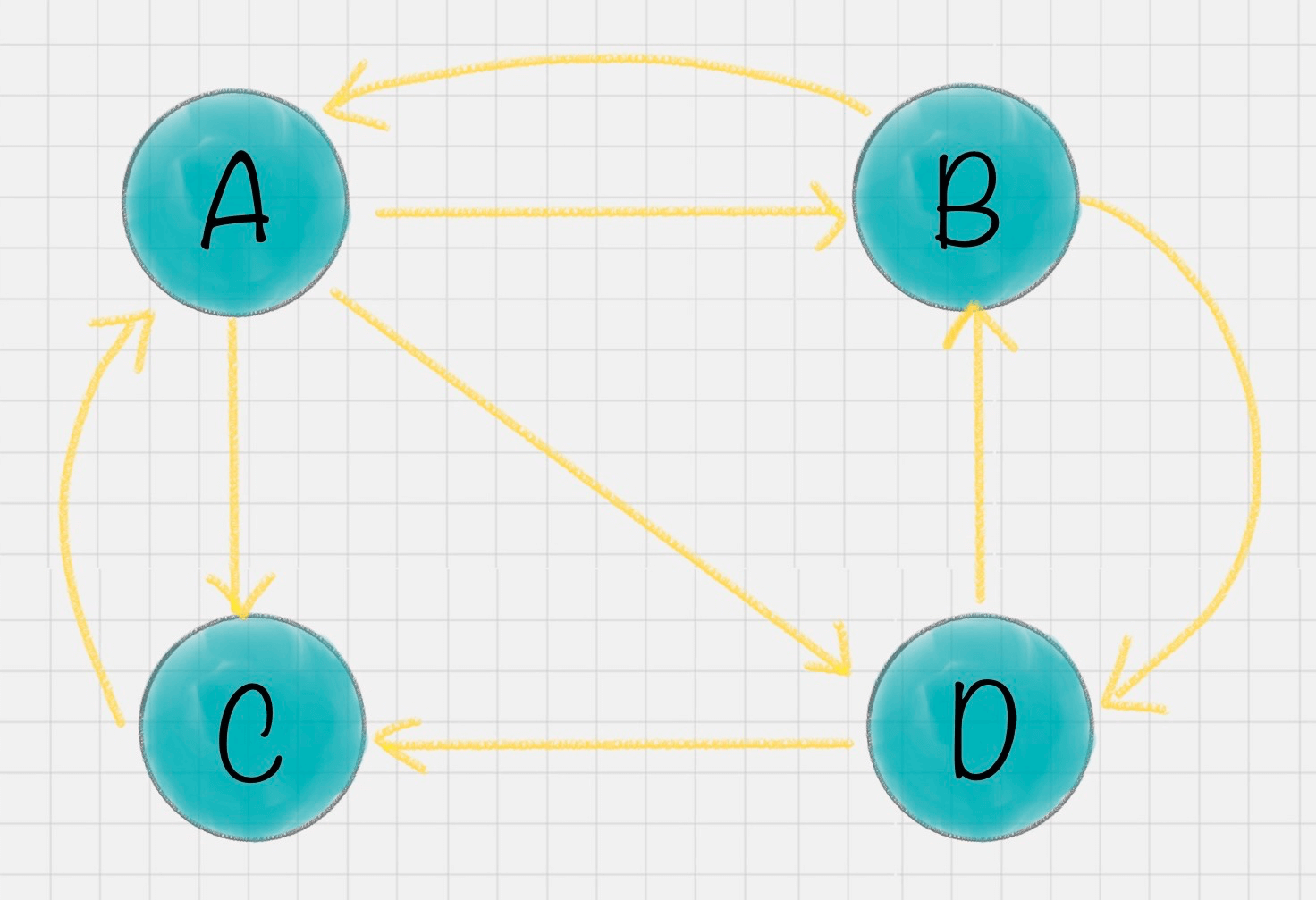
在这个例子中,你能看到 A 有三个出链分别链接到了 B、C、D 上。那么当用户访问 A 的时候,就有跳转到 B、C 或者 D 的可能性,跳转概率均为 1/3。B 有两个出链,链接到了 A 和 D 上,跳转概率为 1/2。这样,我们可以得到 A、B、C、D 这四个网页的转移矩阵 M

A、B、C、D 四个页面的初始影响力都是相同的,即:
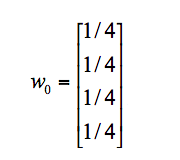
当进行第一次转移之后,各页面的影响力 w1 变为:
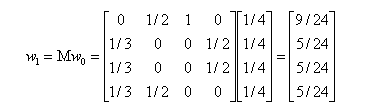
然后我们再用转移矩阵乘以 w1 得到 w2 结果,直到第 n 次迭代后 wn 影响力不再发生变化,可以收敛到 (0.3333,0.2222,0.2222,0.2222),也就是对应着 A、B、C、D 四个页面最终平衡状态下的影响力。
这是一个简化的 PageRank 的计算过程,实际情况会比这个复杂,可能会面临两个问题:
1. 等级泄露(Rank Leak):如果一个网页没有出链,就像是一个黑洞一样,吸收了其他网页的影响力而不释放,最终会导致其他网页的 PR 值为 0。
2. 等级沉没(Rank Sink):如果一个网页只有出链,没有入链,计算的过程迭代下来,会导致这个网页的 PR 值为 0(也就是不存在公式中的 V)。
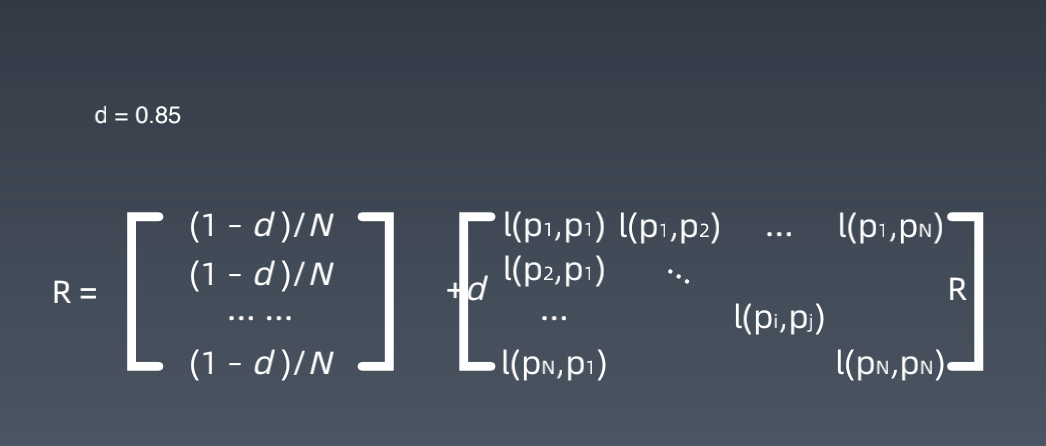
解决简化模型中存在的等级泄露和等级沉没的问题,拉里·佩奇提出了 PageRank 的随机浏览模型。他假设了这样一个场景:用户并不都是按照跳转链接的方式来上网,还有一种可能是不论当前处于哪个页面,都有概率访问到其他任意的页面,比如说用户就是要直接输入网址访问其他页面,虽然这个概率比较小。所以他定义了阻尼因子 d,这个因子代表了用户按照跳转链接来上网的概率,通常可以取一个固定值 0.85,而 1-d=0.15 则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
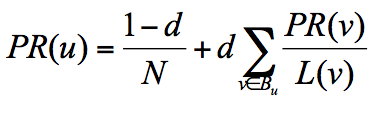
其中 N 为网页总数,这样我们又可以重新迭代网页的权重计算了,因为加入了阻尼因子 d,一定程度上解决了等级泄露和等级沉没的问题。通过数学定理(这里不进行讲解)也可以证明,最终 PageRank 随机浏览模型是可以收敛的,也就是可以得到一个稳定正常的 PR 值。

内容节选自数据分析实战45讲